
GPUStack is an open-source GPU cluster manager designed for running AI models, including LLMs, embedding models, reranker models, vision language models, image generation models, as well as Speech-to-Text and Text-to-Speech models. It allows you to create a unified cluster by combining GPUs from diverse platforms, such as Apple Macs, Windows PCs, and Linux servers. Administrators can deploy models from popular repositories like Hugging Face, allowing developers to access these models as easily as they would access public model services from providers such as OpenAI or Microsoft Azure.
At GPUStack, our mission has always been to make it as simple and seamless as possible for users to manage heterogeneous GPU resources and run the AI models they need—empowering applications such as RAG, AI agents, and other generative AI scenarios.
Delivering an outstanding user experience remains our top priority. With the release of v0.5 and in upcoming versions, we are fully committed to continuously enhancing and refining the overall user experience.
Key updates in GPUStack v0.5 include:
New Model Catalog:
Introduces a curated collection of verified models, simplifying the deployment process, reducing cognitive overhead, and significantly improving deployment efficiency.
Enhanced Windows and macOS Model Support:
Expands support for VLM multimodal models and Tool Calling features to Windows and macOS platforms—no longer limited to Linux environments.
Image-to-Image Generation Support:
Adds image-to-image (image editing) capabilities for image generation models, along with corresponding APIs and a Playground UI for richer use cases.
Improved Model Management:
Adds model startup checks, supports starting and stopping models, and allows manual categorization for models that cannot be automatically identified—making model organization and usage more intuitive.
Scheduler Enhancements:
Improves automatic scheduling priorities by elevating distributed inference above CPU-based inference. Manual GPU selection is now more flexible, supporting multi-GPU scheduling—including both single-node multi-GPU (vLLM) and multi-node multi-GPU (llama-box) setups.
Expanded Integration Capabilities:
Adds support for AMD GPUs, extends GPUStack Provider in Dify to support STT and TTS speech models, introduces GPUStack Provider integration for RAGFlow, and resolves integration issues with FastGPT.
This release includes over 60 improvements, fixes, stability enhancements, and user experience upgrades, delivering a more powerful, streamlined platform to better support a wide range of application scenarios.
For more information about GPUStack, visit:
GitHub repo: https://github.com/gpustack/gpustack
User guide: https://docs.gpustack.ai
Feature Highlights
Model Catalog
GPUStack now supports directly searching for and deploying models from public model repositories such as Hugging Face and ModelScope. Combined with our multi-version inference engine feature, users can deploy and experience newly released frontier models at any time without needing to upgrade GPUStack itself.
However, this flexibility can sometimes introduce challenges for newer users: with the vast variety of models available on Hugging Face and ModelScope, it can be difficult to determine which model to deploy.
To further streamline the deployment experience, GPUStack v0.5 introduces a new Model Catalog. The Catalog provides a curated set of verified models and simplifies the deployment process, significantly reducing the cognitive load for users:
- Model families: Related models are grouped into families, allowing users to choose a family based on their needs, with options like weight size and quantization precision easily configurable—further simplifying the deployment process.
- Automatic download source selection: GPUStack intelligently chooses the fastest download source between Hugging Face and ModelScope based on network conditions, with no manual configuration required.
- Pre-configured parameters: GPUStack automatically presets model-specific configuration parameters as needed. For example, for models supporting Tool Calling, the system will auto-enable the necessary settings to activate this feature.

In the upcoming v0.6 and future releases, GPUStack will continue to enhance and optimize the Catalog, improving both the efficiency and success rate of model deployments. By reducing trial-and-error during setup, we aim to make it faster, easier, and more reliable for users to deploy the models they need.
Enhanced Windows and macOS Model Support
In previous versions, support for VLM (Vision-Language Models) and model Tool Calling capabilities was built on the vLLM backend, limiting these features to Linux environments. To broaden platform compatibility and better meet the needs of Windows and macOS users, we’ve enhanced the llama-box backend.
Now, whether users are on Linux, Windows, or macOS, they can seamlessly deploy and run VLM models across platforms—including models like Qwen2-VL, MiniCPM-V, and MiniCPM-o. Additionally, llama-box now automatically enables Tool Calling for models that support it, delivering a consistent and powerful model experience across all major operating systems.
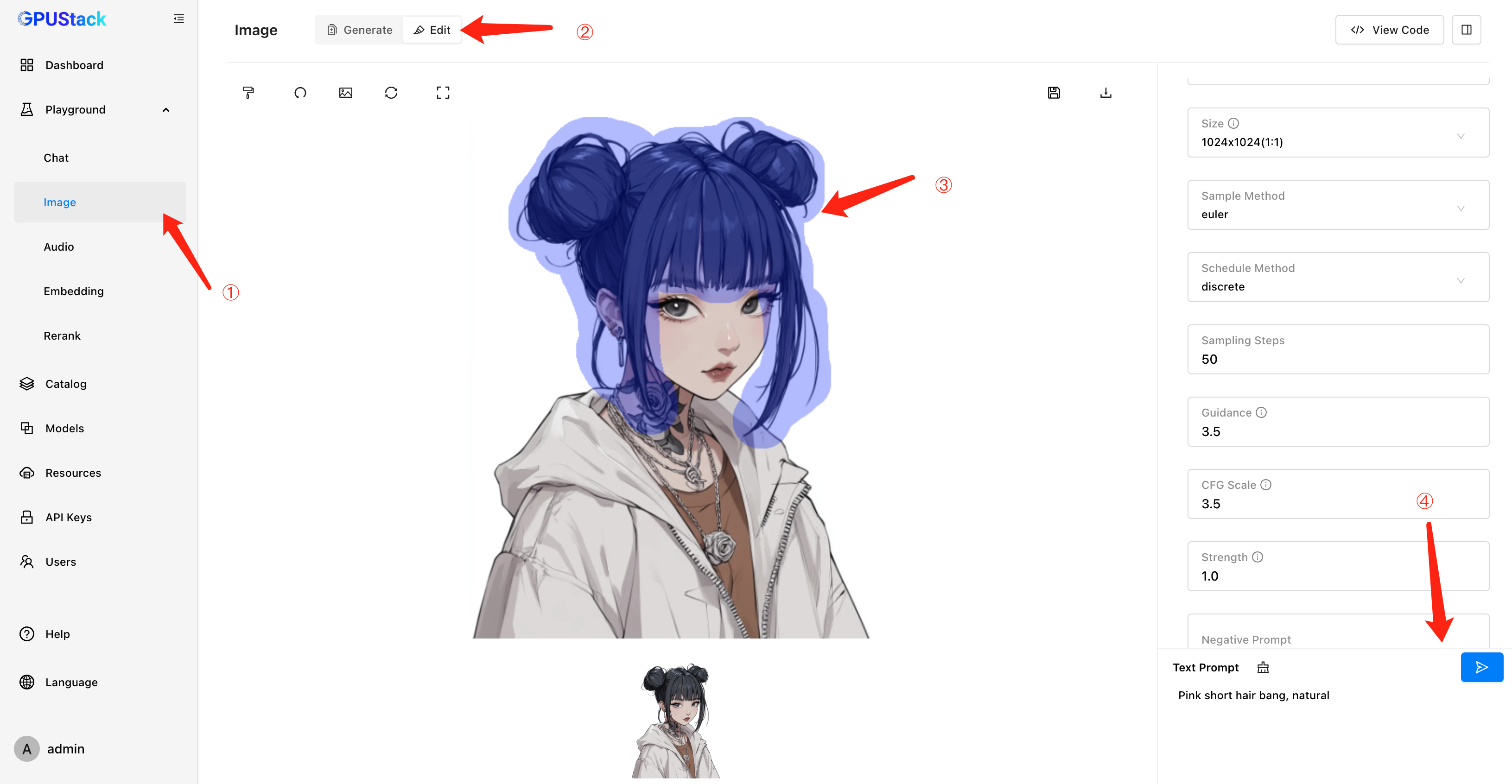
Image-to-Image Support
GPUStack introduced text-to-image model support in v0.4, empowering users with image generation capabilities. In v0.5, we’ve taken it a step further by adding image-to-image (image editing) support. Users can now leverage this functionality through both the Image Edit API and an intuitive Playground UI for interactive editing and debugging.
This enhancement expands the application scenarios for image models, meeting more diverse user needs and enabling richer creative and image-based workflows.

Improved Model Management
Model deployment and management are core features of GPUStack. To further enhance the user experience, v0.5 introduces a model startup validation feature. Now, GPUStack ensures a model has fully launched and is capable of serving inference requests before making it available in the Playground—eliminating issues caused by trying to use models that aren’t ready.
We’ve also improved the experience around stopping model instances. Previously, users needed to manually set the replica count to zero, which wasn’t very intuitive. In v0.5, GPUStack adds straightforward start and stop controls for model instances, making management easier and more user-friendly.
Additionally, we’ve enhanced automatic model classification. GPUStack now better recognizes and categorizes models automatically. For models that still cannot be classified automatically, users can now manually assign categories to keep their deployments organized and easy to manage.

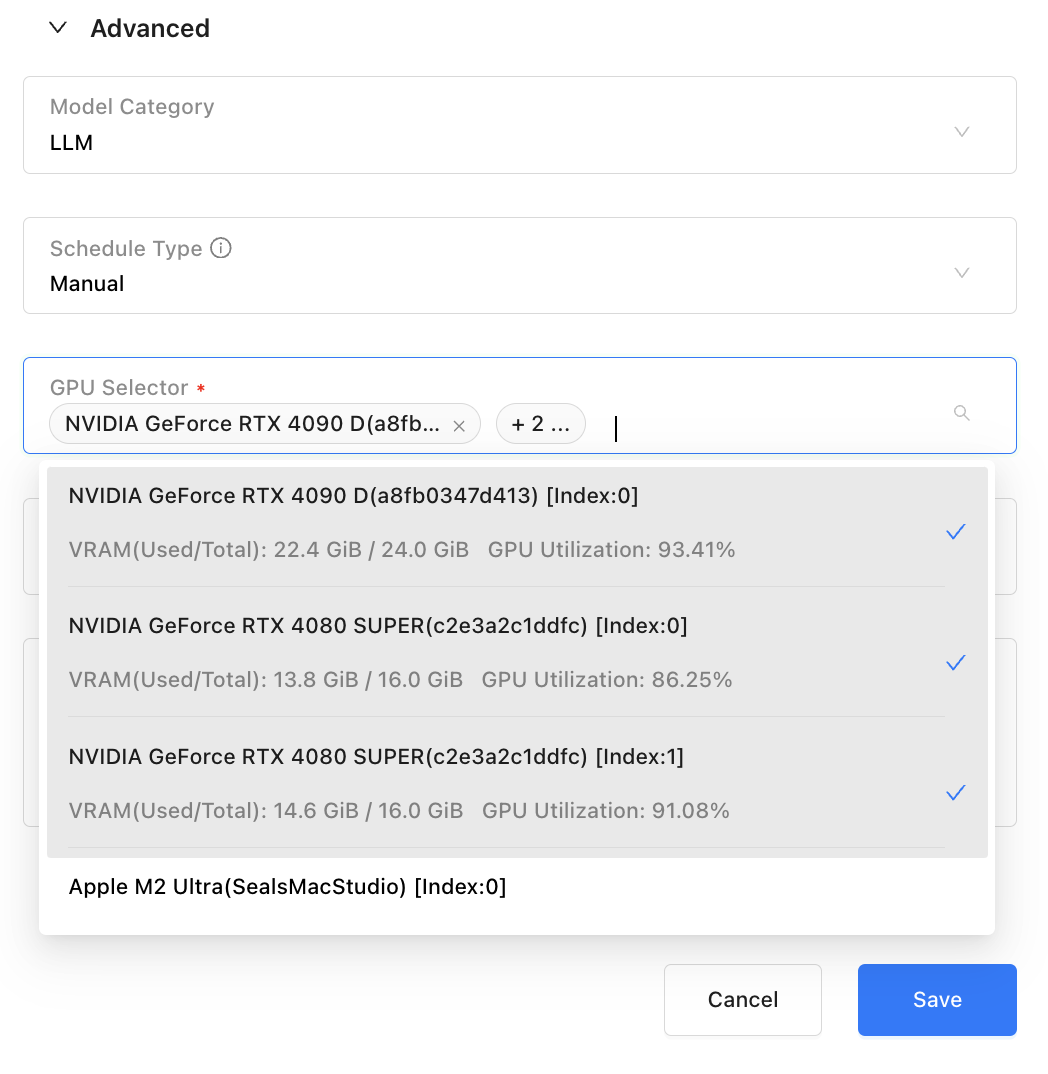
Scheduling Optimizations
To better meet users’ real-world deployment and scheduling needs—and after extensive testing of distributed inference performance and stability—GPUStack v0.5 introduces priority optimizations for automatic scheduling. Distributed inference now has a higher priority than CPU inference. The new automatic scheduling priority is:
Single-GPU Inference > Multi-GPU Inference (Single Node) > Multi-GPU Distributed Inference (Multi-Node) > CPU & GPU Hybrid Inference > Pure CPU Inference
This optimization ensures that high-performance resources are prioritized for model execution, delivering better inference performance and efficiency.

To provide even more flexible GPU resource control, v0.5 also enhances manual GPU selection. Users can now select multiple GPUs—supporting both single-node multi-GPU setups (vLLM) and multi-node distributed setups (llama-box). This offers greater freedom and precision when allocating GPU resources, enabling GPUStack to better adapt to a wide variety of deployment scenarios.
Expanded Integration Capabilities
GPUStack is committed to seamless integration with a wide range of third-party applications and frameworks, providing robust model serving capabilities for real-world generative AI applications. Integration with popular generative AI frameworks—such as Dify, RAGFlow, and FastGPT—has been one of our key focuses.
Following the addition of speech model (STT and TTS) support in GPUStack, we have further enhanced the GPUStack Provider for Dify.
Users can now easily connect to GPUStack-deployed speech models directly through Dify.
Together, GPUStack and Dify enable a richer set of generative AI capabilities.
We have also added a GPUStack Provider in the latest version of RAGFlow, enabling integration with GPUStack-hosted models including LLMs, embedding models, rerankers, as well as STT and TTS models—offering greater flexibility for building efficient RAG workflows.

At the same time, in v0.5, we resolved previous integration issues with FastGPT, allowing FastGPT users to seamlessly integrate GPUStack-deployed model services through OneAPI.
For other large model application frameworks (such as LangChain and LlamaIndex), GPUStack provides a standard OpenAI-compatible API, making integration straightforward.
If you encounter any issues while integrating GPUStack with your applications, please feel free to reach out—we’re always ready to help!
Expanded Hardware Support
GPUStack v0.5 adds support for AMD GPUs!
You can refer to the tutorial for setup instructions:
https://docs.gpustack.ai/latest/installation/amd-rocm/online-installation/
GPUStack now provides offline container images for multiple acceleration frameworks, including NVIDIA CUDA, AMD ROCm, Ascend CANN, Moore Threads MUSA, as well as images for CPU inference (x86 architecture with AVX2 support, ARM64 architecture with NEON support). These images allow users to flexibly build heterogeneous GPU resource pools by running the appropriate inference environments on different types of devices—meeting a wide variety of model deployment needs.
We are continuously expanding GPUStack’s hardware compatibility and are actively working to support Hygon DCUs and Cambricon MLUs.
Note: GPUStack currently requires Python >= 3.10. If your host system’s Python version is lower than 3.10, we recommend using Conda to create a compatible environment.
Other Features and Fixes
GPUStack v0.5 also introduces many improvements and bug fixes based on user feedback and usage pain points, such as:
- Added container installation guides for NVIDIA, AMD, Ascend, and Moore Threads GPUs/NPUs
- Automatically selects the fastest download source for required tools, eliminating the need for manual selection
- Fixed versions of built-in vLLM and vox-box backends to ensure consistency across multi-node setups and reinstallation scenarios
- Fixed incorrect parallel card allocation during automatic scheduling with the vLLM backend
- Fixed inaccurate memory estimation when deploying GPTQ and AWQ quantized models with the vLLM backend
- Solved an issue where the llama-box backend would allocate a small amount of GPU memory even when performing pure CPU inference on GPU nodes
These enhancements significantly improve GPUStack’s usability and stability, delivering a smoother overall experience.
For a full list of enhancements and fixes, please check the complete changelog:
https://github.com/gpustack/gpustack/releases/tag/v0.5.0
Join Our Community
For more information about GPUStack, please visit our GitHub repository: https://github.com/gpustack/gpustack.
If you have any suggestions or feedback about GPUStack, feel free to open an issue on GitHub.
Before trying out GPUStack or submitting an issue, we kindly ask you to give us a Star ⭐️ on GitHub to show your support.
We also warmly welcome contributions from the community — let’s build this open-source project together!












{kind=link}