GPUStack unlocks the full potential of your hardware with intelligent optimization for LLM deployment and inference.
Open-source inference engines deliver state-of-the-art performance, but require significant expertise and effort to unlock their full potential. GPUStack solves this complexity.
Manual tuning, complex configurations, and suboptimal performance across different hardware platforms.
Automated optimization that delivers significant performance gains out of the box.
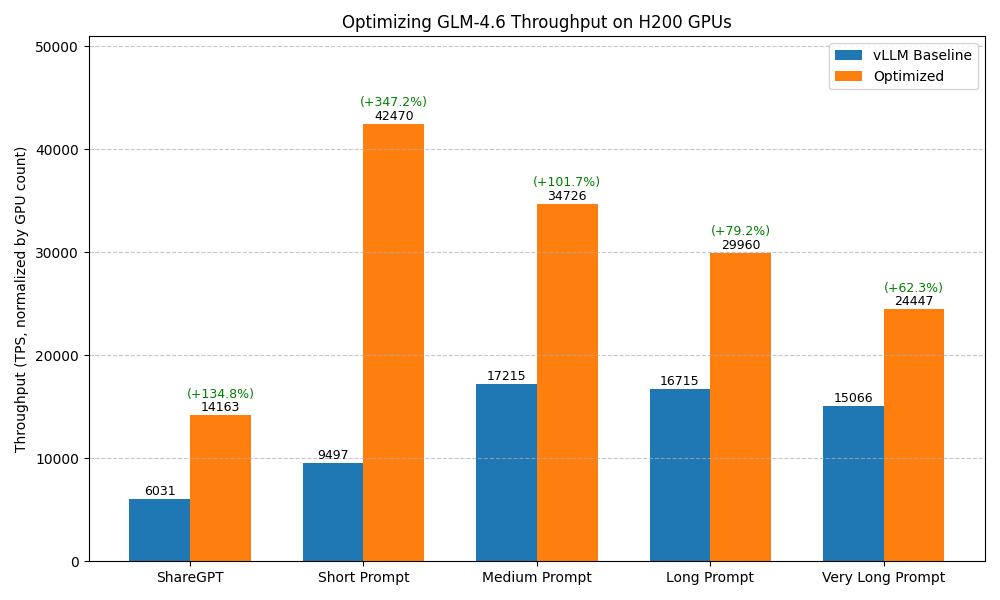
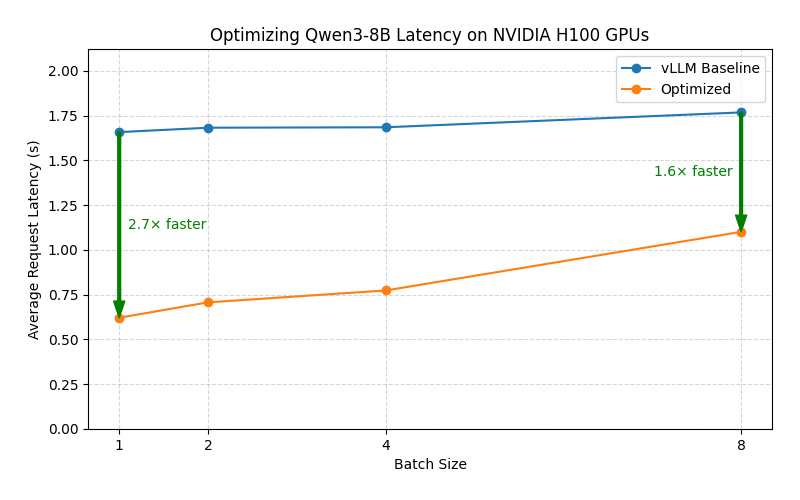
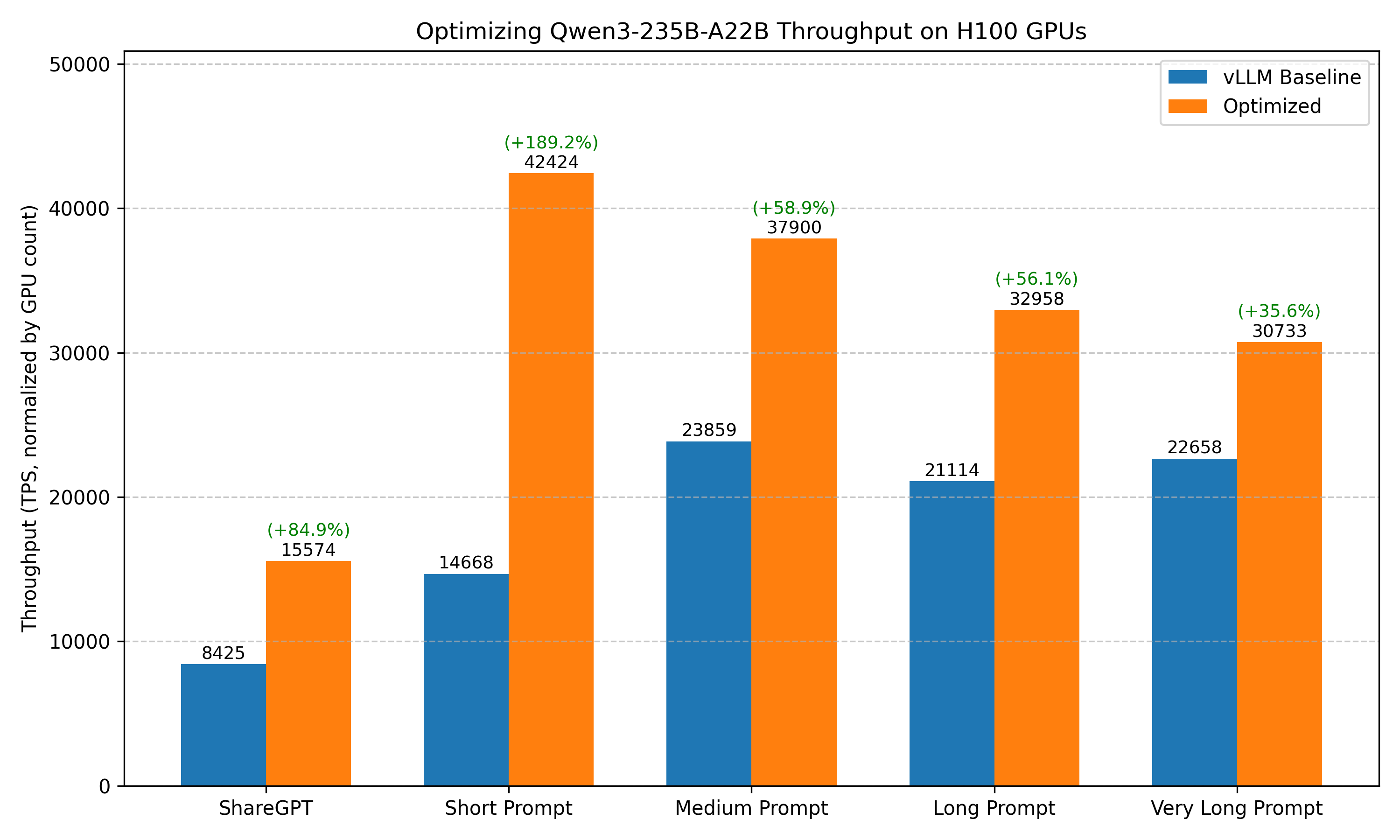
GPUStack tuned deployment achieves significant performance gains compared to unoptimized vLLM baseline.
Different scenarios demand different optimization strategies. GPUStack provides flexible deployment modes.
Optimized for high throughput under high request concurrency. Perfect for batch processing and high-volume APIs.
Optimized for low latency under low request concurrency. Ideal for real-time interactive applications.
Runs at full precision and prioritizes compatibility. Ensures maximum model accuracy and stability.
Fully customizable optimization parameters tailored to your specific requirements and constraints.
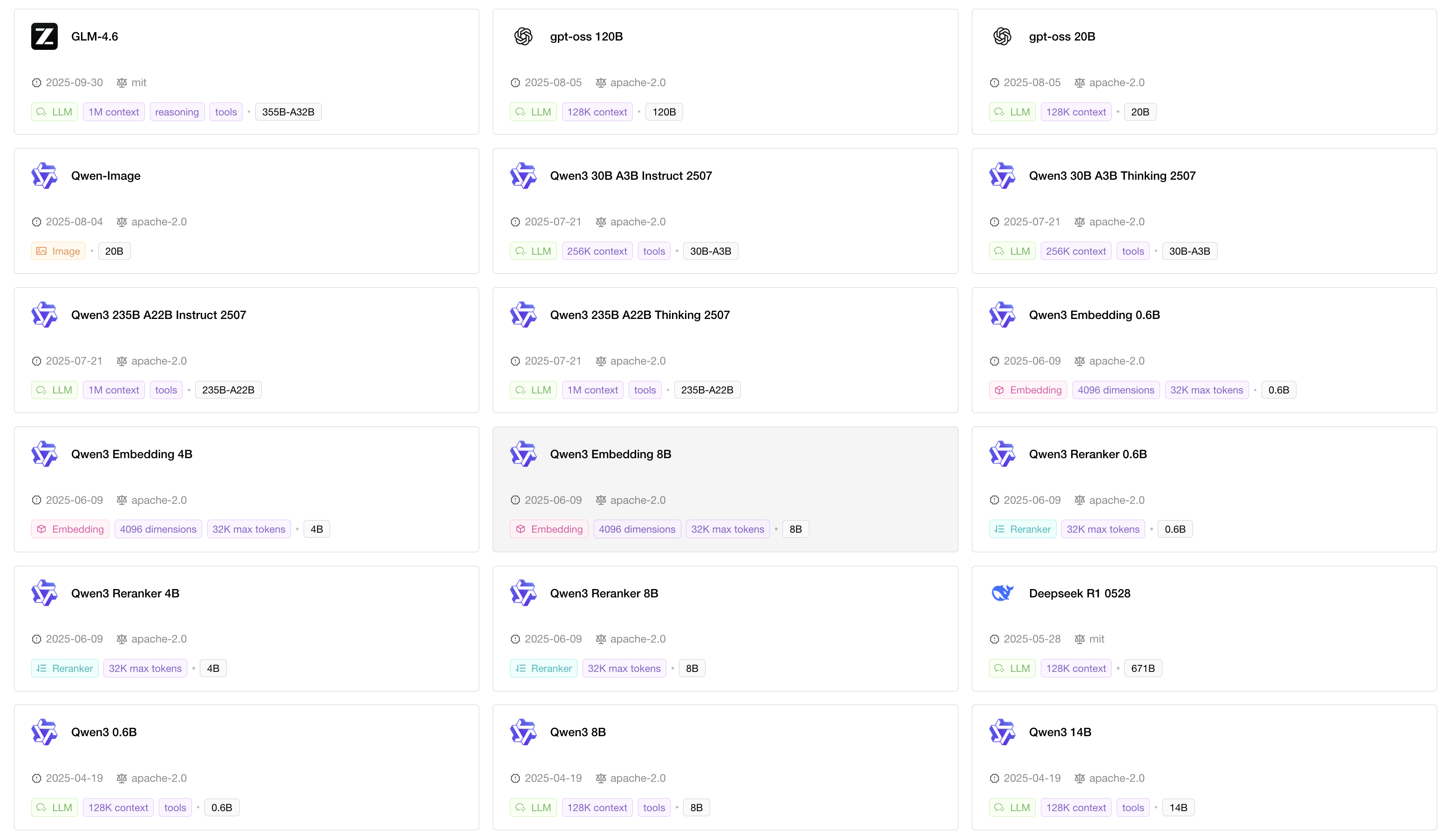
Pluggable backend and engine support lets you run state-of-the-art open-source models from day one.








Deploy across any infrastructure, anywhere in the world.

Leverage your existing GPU servers with full control over your infrastructure.

Deploy on any Kubernetes cluster with seamless orchestration and management.

AWS, DigitalOcean, Alibaba Cloud, and more — dynamically scale GPU resources.
GPUStack gives you the power to see everything your models do. From real-time performance metrics to historical trends, track every inference, every millisecond, and every resource your LLMs consume.

Live performance tracking

Performance analytics
GPU/CPU utilization

Automated tuning
GPUStack enables teams to efficiently manage models, inference engines, and compute resources while collaborating seamlessly.
From GPU clusters to users and API keys, keep everything organized and under control.
GPUStack provides the enterprise capabilities needed to deploy LLMs at scale with confidence.
Seamless enterprise login and identity management
Manage who can access or modify models within your team
Control usage organization-wide with rate limits
Ensure uninterrupted model service with failover
Join thousands of developers and enterprises already using GPUStack to deploy LLMs at scale.

{kind=link}