
GPUStack is an open-source GPU cluster manager designed for running AI models, including LLMs, embedding models, reranker models, vision language models, image generation models, as well as Speech-to-Text and Text-to-Speech models. It allows you to create a unified cluster by combining GPUs from diverse platforms, such as Apple Macs, Windows PCs, and Linux servers. Administrators can deploy models from popular repositories like Hugging Face, allowing developers to access these models as easily as they would access public model services from providers such as OpenAI or Microsoft Azure.
As GPUStack continues to gain adoption for RAG, AI Agents, and other diverse use cases, we are proud to introduce the powerful GPUStack v0.4, designed to address high-priority needs.
Key Updates in GPUStack v0.4:
1. Support for New Model Types:
• Image Generation Models.
• Speech-to-Text (STT) models.
• Text-to-Speech (TTS) models.
2. Inference Engine Version Management:
• Pin specific inference engine versions to individual models for greater flexibility.
3. New Playground UI:
• Added interactive UIs for STT, TTS, T2I, Embedding and Rerank.
4. Offline Support:
• Enables offline installation, container images, and deployment of local models.
5. Extended Compatibility:
• Broader OS support, including legacy operating systems.
6. Bug Fixes and Optimizations:
• Addressed numerous community-reported issues with significant improvements and enhancements.
This release boosts GPUStack’s adaptability and stability, meeting the growing needs of diverse AI applications.
For more information about GPUStack, visit:
GitHub repo: https://github.com/gpustack/gpustack
User guide: https://docs.gpustack.ai
Key Features
Support for Image Generation models
GPUStack now supports image generation models! With the integration of stable-diffusion.cpp into the llama-box, we’ve added support for image generation models such as Stable Diffusion and FLUX. Additionally, we’ve expanded compatibility with Ascend NPUs and Moore Threads GPUs.
GPUStack runs on Linux, macOS, and Windows, leveraging NVIDIA GPUs, Apple Metal GPUs, Ascend NPUs, and Moore Threads GPUs to power image generation models.
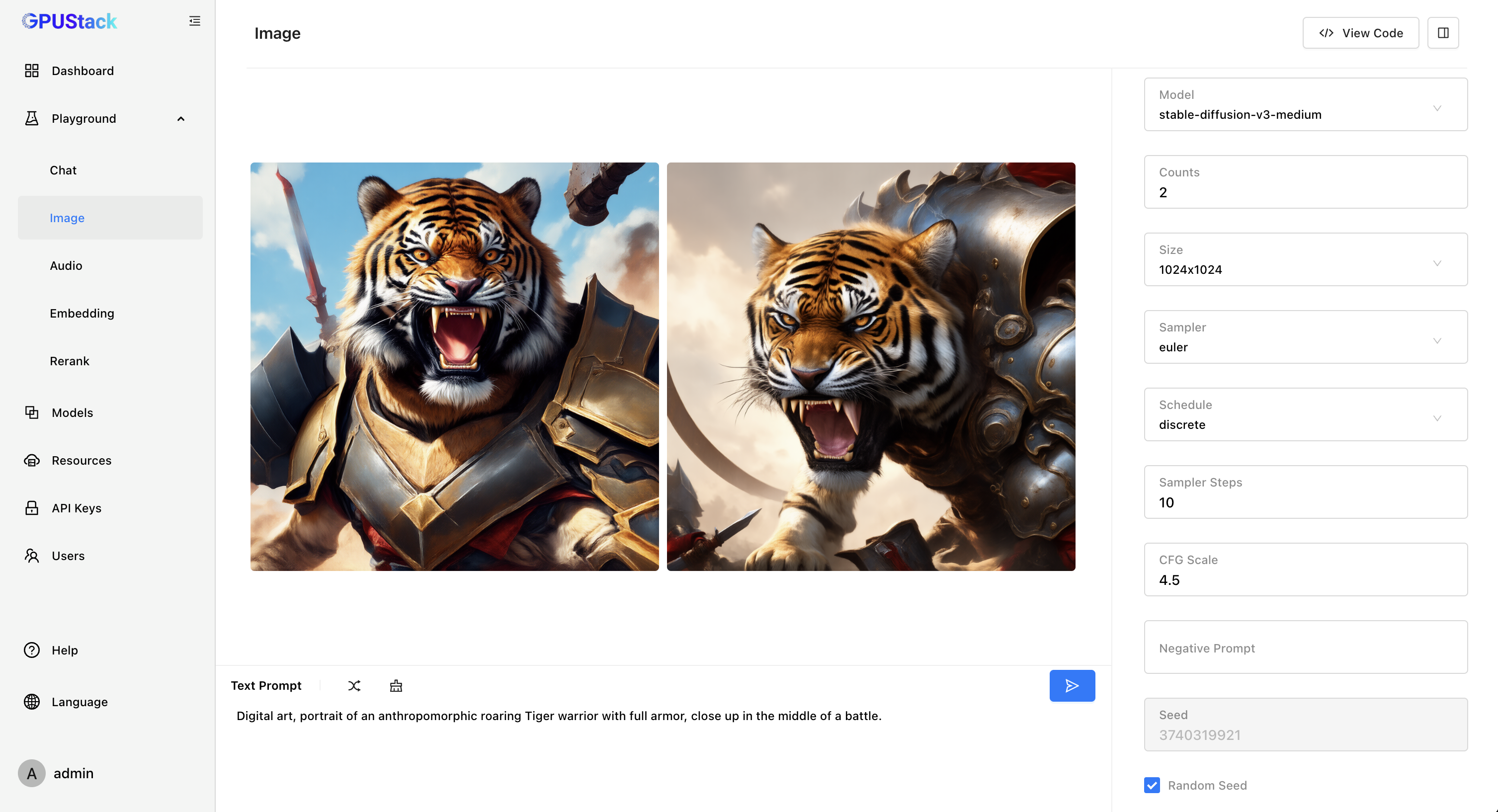
To make it easier to get started, we offer a selection of all-in-one models, please refer to:
https://huggingface.co/collections/gpustack/image-672dafeb2fa0d02dbe2539a9
Support for Audio Models
GPUStack now supports audio models with the launch of the vox-box inference engine! [GitHub: https://github.com/gpustack/vox-box]
vox-box enables inference for Text-to-Speech (TTS) and Speech-to-Text (STT) models, fully compatible with the OpenAI API. It currently integrates backends including Whisper, FunASR, Bark, and CosyVoice.
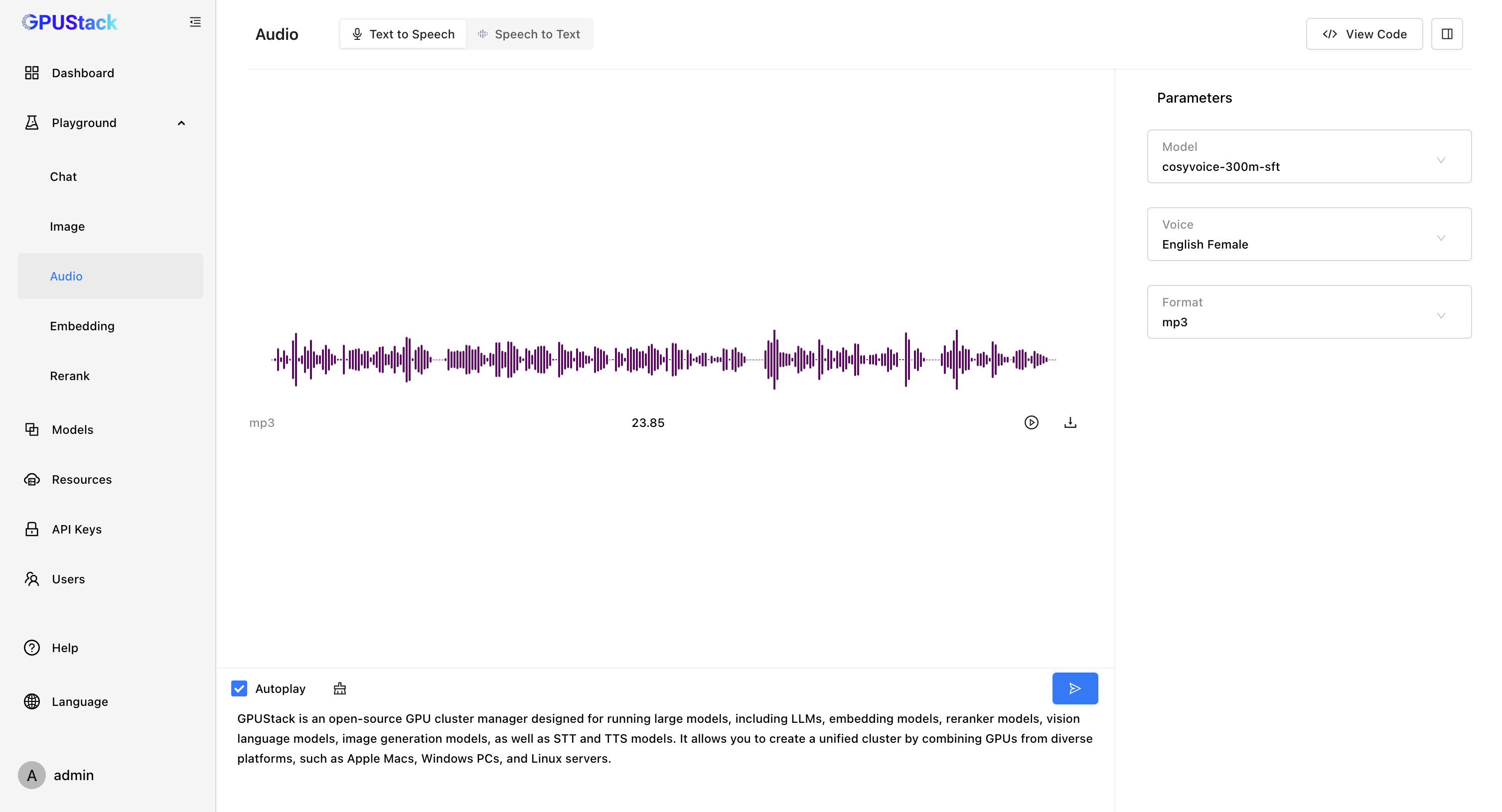
- Text To Speech
- Speech To Text
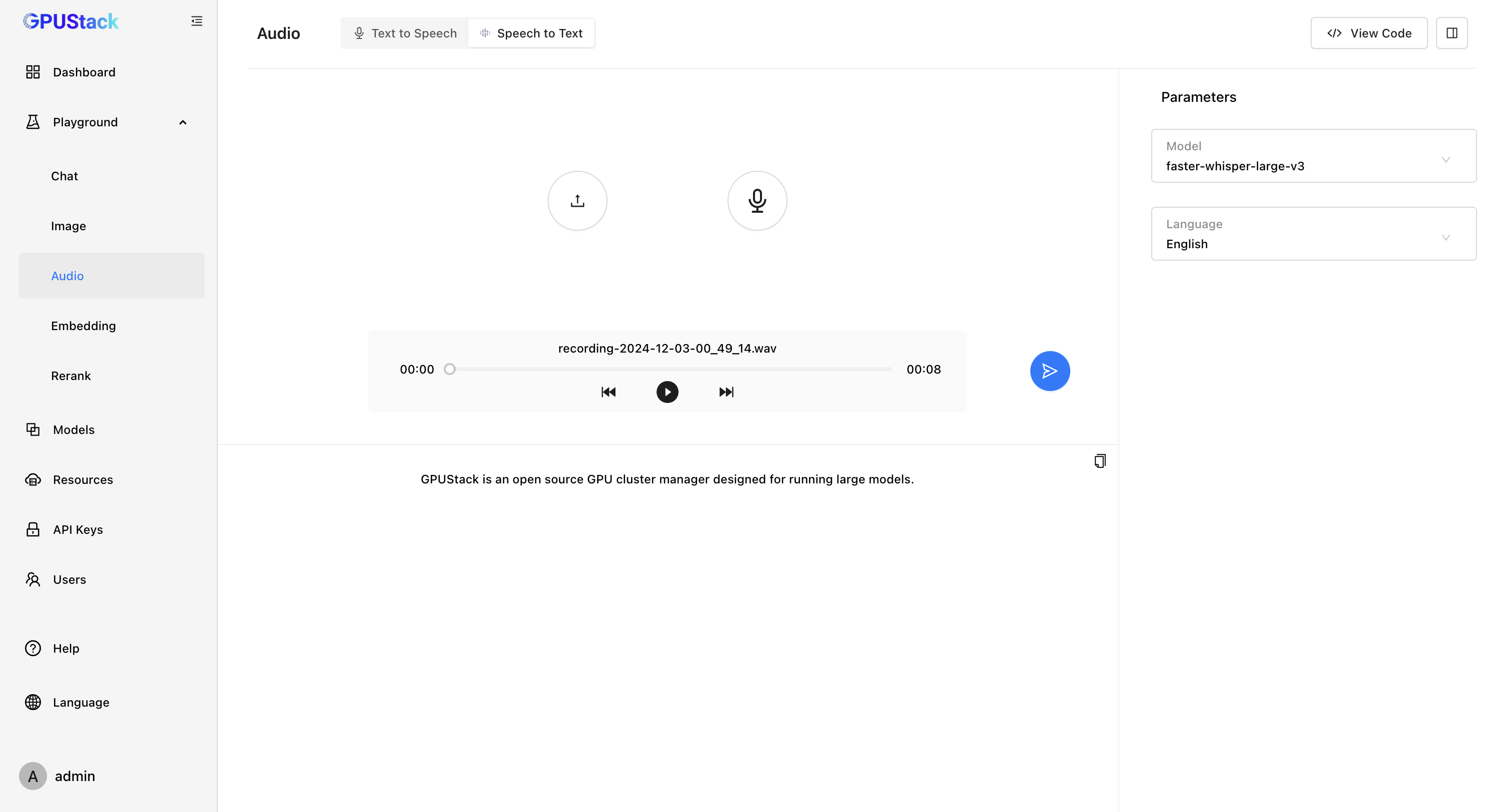
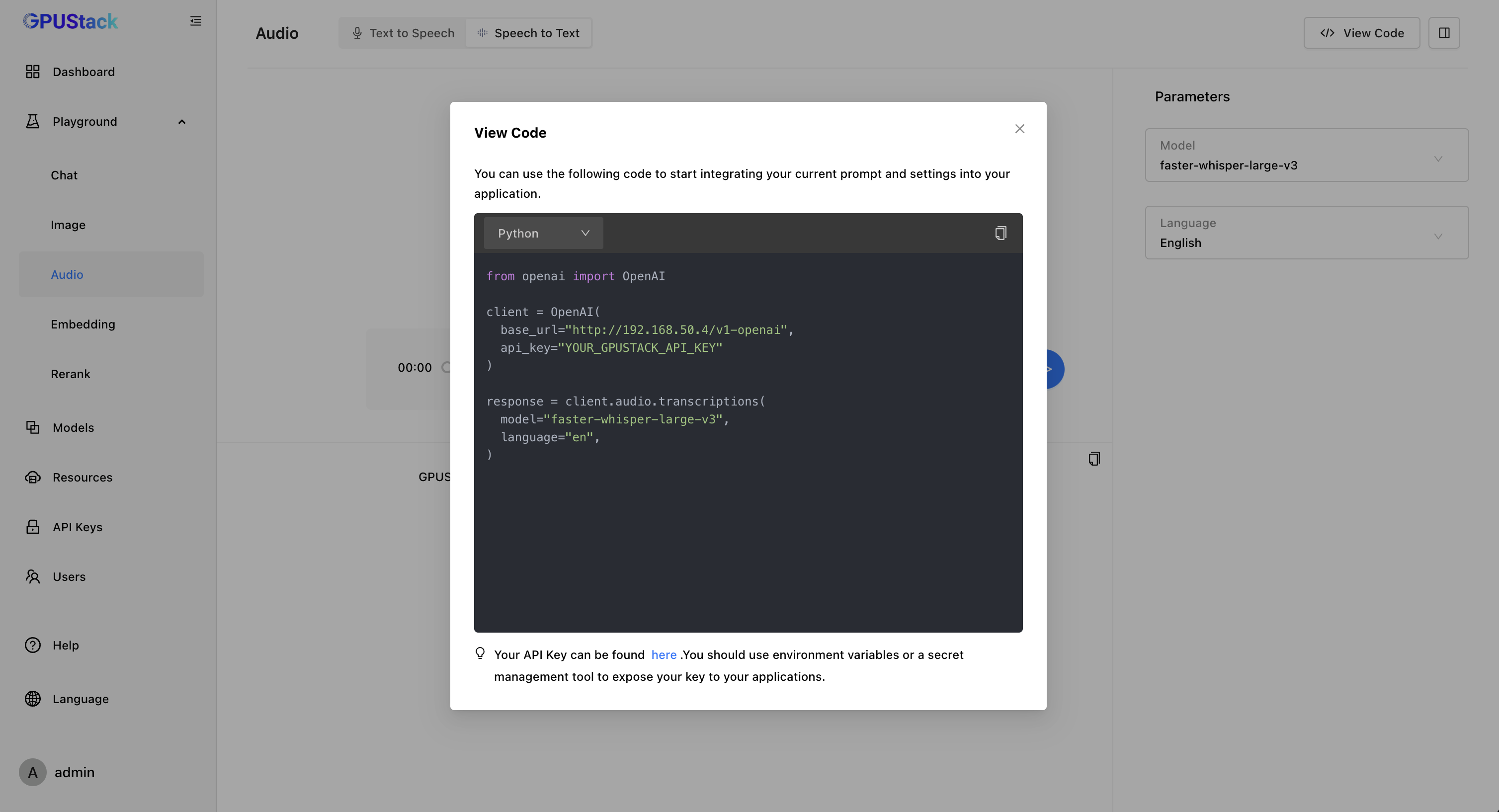
With vox-box, GPUStack supports Speech-to-Text models like Whisper, Paraformer, Conformer, and SenseVoice, as well as Text-to-Speech models such as Bark and CosyVoice. We’re continuously expanding support for more models while optimizing their performance and quality.
For the full list of supported models, refer to:
https://github.com/gpustack/vox-box#supported-models
Inference Engine Version Management
Frequent updates to inference engines are essential to support new AI models, but they can introduce bugs or break compatibility with existing ones. This creates a dilemma: upgrading for new features risks destabilizing older models, while sticking with older versions limits access to innovations.
GPUStack resolves this by allowing users to pin specific inference engine versions for each model. During deployment, you can specify the version that best suits your needs, and GPUStack will ensure the model runs with the specified engine.
This decoupled architecture lets multiple versions coexist, enabling seamless support for both cutting-edge and legacy models. It provides stability for existing applications while offering the flexibility to adopt new advancements without compromise.
Expanded Playground UI
The Playground now supports more models, including Image Generation, Speech-to-Text (STT), Text-to-Speech (TTS), Embedding, and Rerank models, enabling direct testing within the UI.
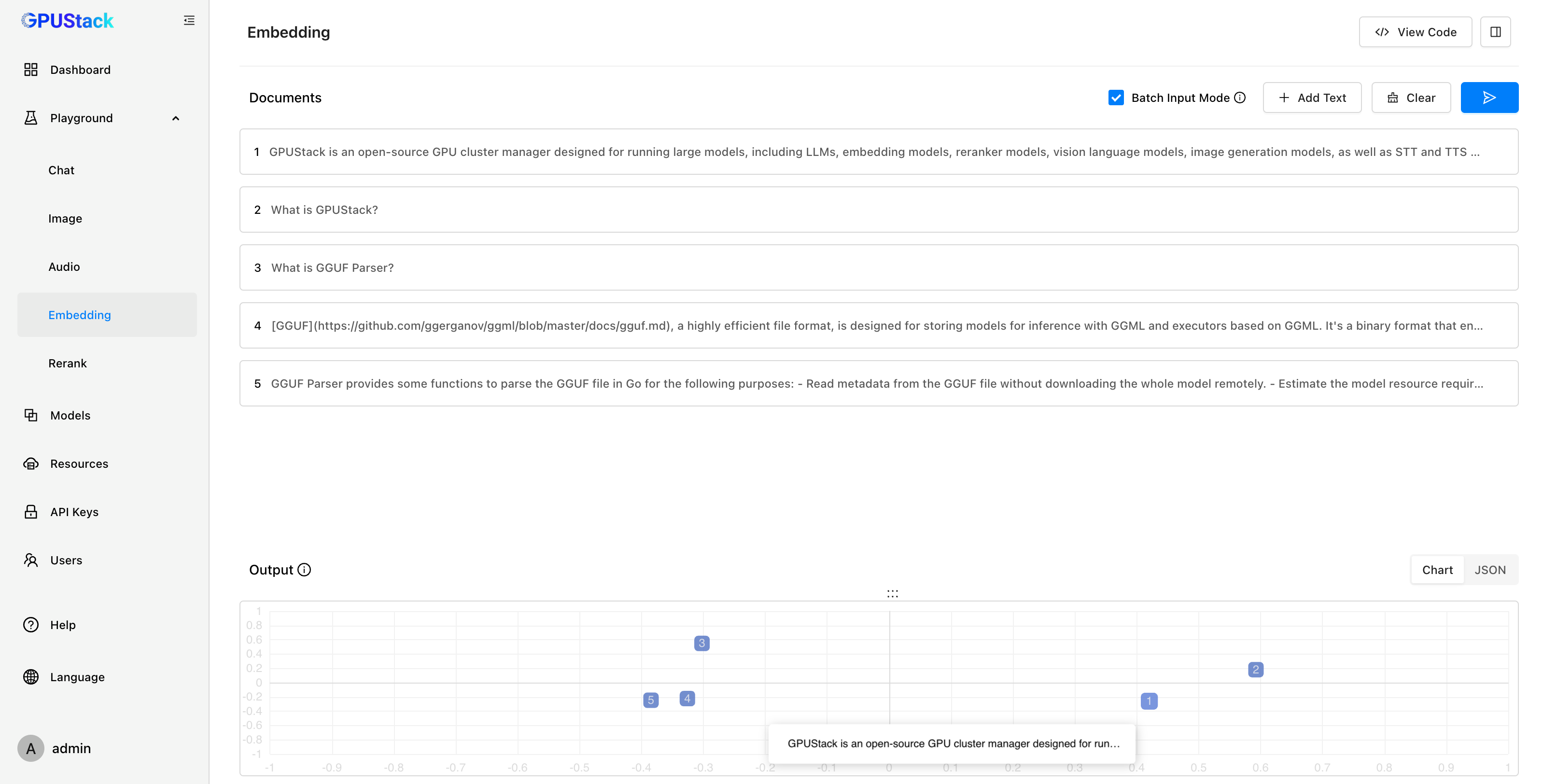
For Embedding models, the Playground offers a visual comparison chart that uses PCA to project embedding vectors into 2D, making text similarity analysis more intuitive. A View Code button provides API examples for easy integration.
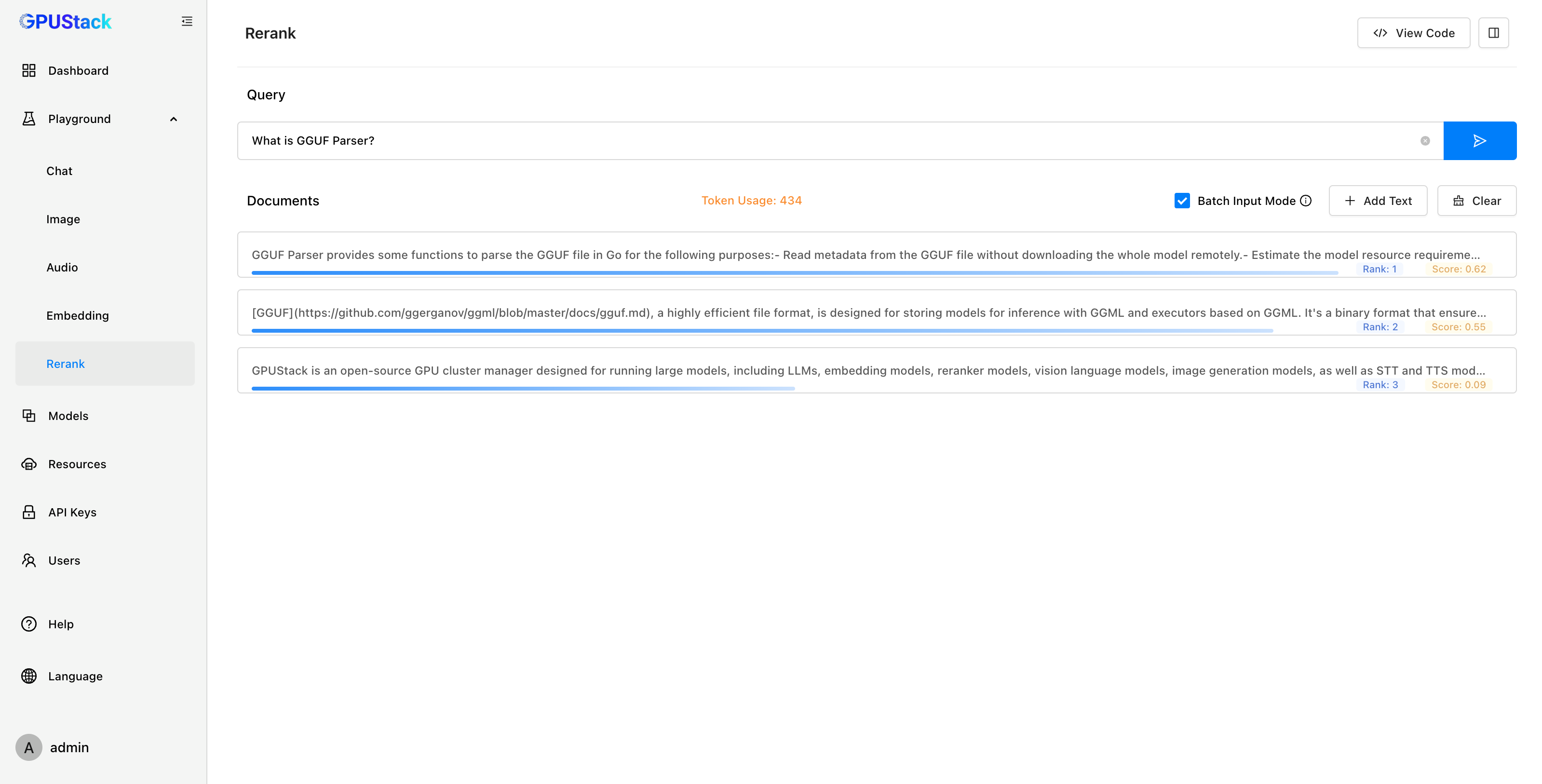
The Playground now includes an interface for testing Rerank models. Users can input a Query and a set of Documents, and the model will rank them by relevance, displaying a score for each. This enables users to evaluate the model’s ranking accuracy and understanding of the input. A View Code button provides API examples for easy integration.
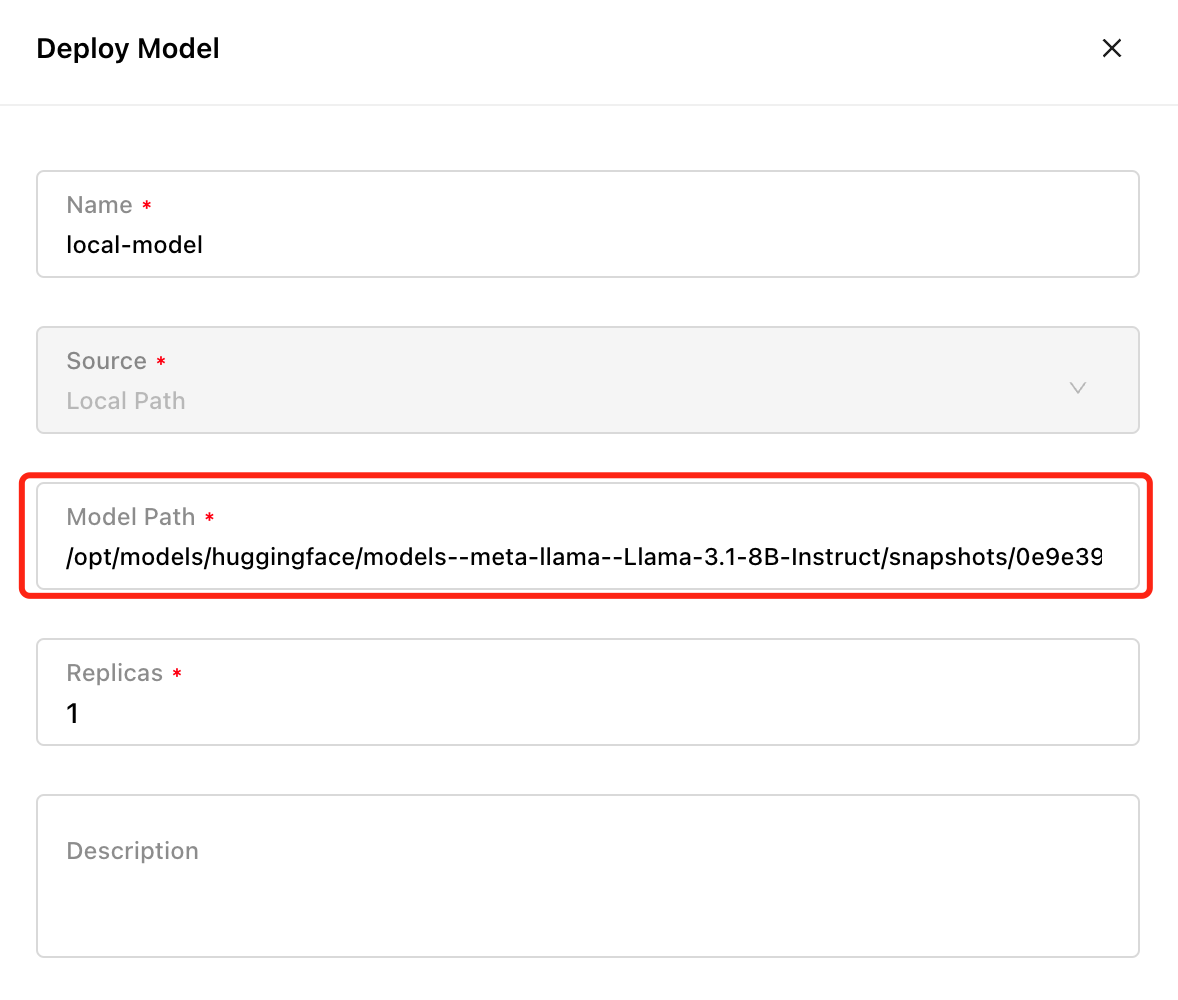
Support for Deploying Models from Local Paths
To support offline use cases, reuse pre-downloaded models, and deploy locally fine-tuned models, GPUStack now allows you to deploy models from local paths, in addition to repositories from Hugging Face, ModelScope, and Ollama Registry.
Users can download models in advance using tools like huggingface-cli, modelscope CLI, or others, and upload the model files to all nodes. During deployment, simply select the Local Path option and specify the absolute path to the model files. Ensure the model files are uploaded to all nodes to ensure they can be correctly loaded and run on any node in the cluster.
Offline Support
GPUStack now supports offline installation and operation, offering two installation methods: Python Installation and Docker Installation.
- Python Installation: The new version provides offline installation instructions and documentation, enabling users to set up GPUStack in air-gapped environments.
- Docker Installation: GPUStack v0.4 offers offline container images for various platforms, including CUDA, NPU (CANN), MUSA, and CPU. Below are example commands to run the containers:
- CUDA 12 (NVIDIA Driver 12.4 or higher), requires NVIDIA Container Runtime:
xxxxxxxxxxdocker run -d --gpus all -p 80:80 --ipc=host \ -v gpustack-data:/var/lib/gpustack gpustack/gpustack:0.4.0- Ascend NPU (NPU Driver 24.1 rc2 or higher), requires Ascend Container Runtime:
xxxxxxxxxxdocker run -d -p 80:80 --ipc=host \ -e ASCEND_VISIBLE_DEVICES=0-7 \ -v gpustack-data:/var/lib/gpustack gpustack/gpustack:0.4.0-npu- MUSA (Moore Threads) (rc3.10 or higher), requires MT Container Toolkits:
xxxxxxxxxxdocker run -d -p 80:80 --ipc=host \ -v gpustack-data:/var/lib/gpustack gpustack/gpustack:0.4.0-musa- CPU (AVX2 or NEON)
xxxxxxxxxxdocker run -d -p 80:80 -v gpustack-data:/var/lib/gpustack gpustack/gpustack:0.4.0-cpuFor detailed configuration instructions, refer to GPUStack’s documentation as well as the hardware vendor’s official guides to ensure proper setup and compatibility.
Manual GPU Allocation and Custom Multi-GPU Splitting for GGUF Models
In previous versions of GPUStack, the system automatically allocated GPUs for GGUF models based on available GPUs and their remaining memory. While this automated approach works for many scenarios, it may not be ideal for all use cases.
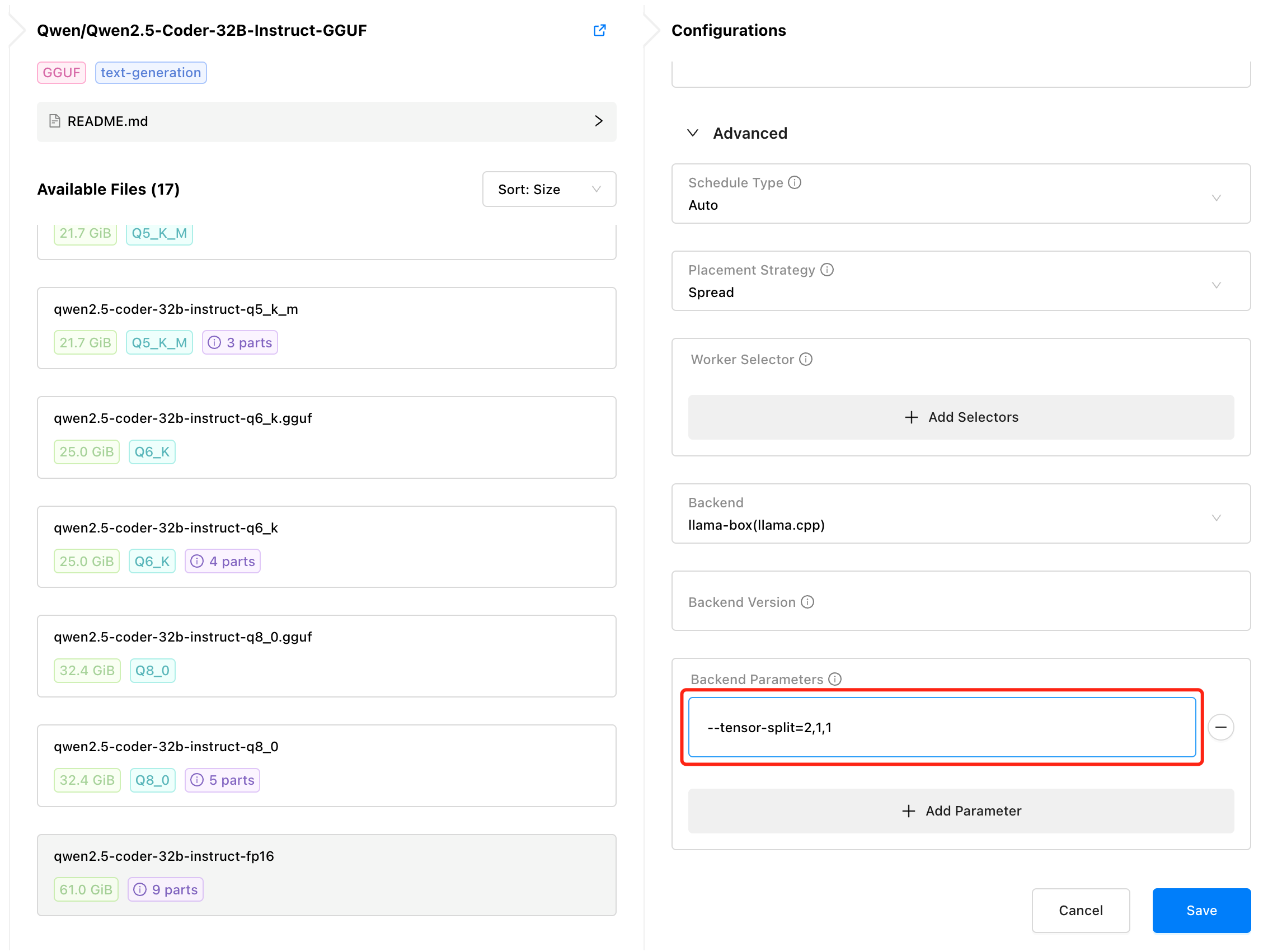
With the release v0.4, GPUStack offers more flexibility by allowing users to manually control GPU allocation and define custom splitting ratios across multiple GPUs. The --tensor-split parameter lets you specify the number of GPUs and how the model should be distributed across them, providing finer control over resource usage:
• --tensor-split=1,1: Allocates 2 GPUs with an even 1:1 split.
• --tensor-split=2,1,1: Allocates 3 GPUs with a 2:1:1 split.
• --tensor-split=10,16,20,20: Allocates 4 GPUs with a custom split of 10:16:20:20 based on available GPU memory.
Optimized Resource Allocation and Scheduling for GGUF Models
In GPUStack v0.4, we’ve improved the gguf-parser to provide more precise resource estimations for models. Additionally, this version can now calculate actual GPU memory usage based on the custom context size specified during model deployment.
These updates help optimize scheduling decisions, reduce the risk of out-of-memory (OOM) errors during resource conflicts, and improve the overall stability of model services.
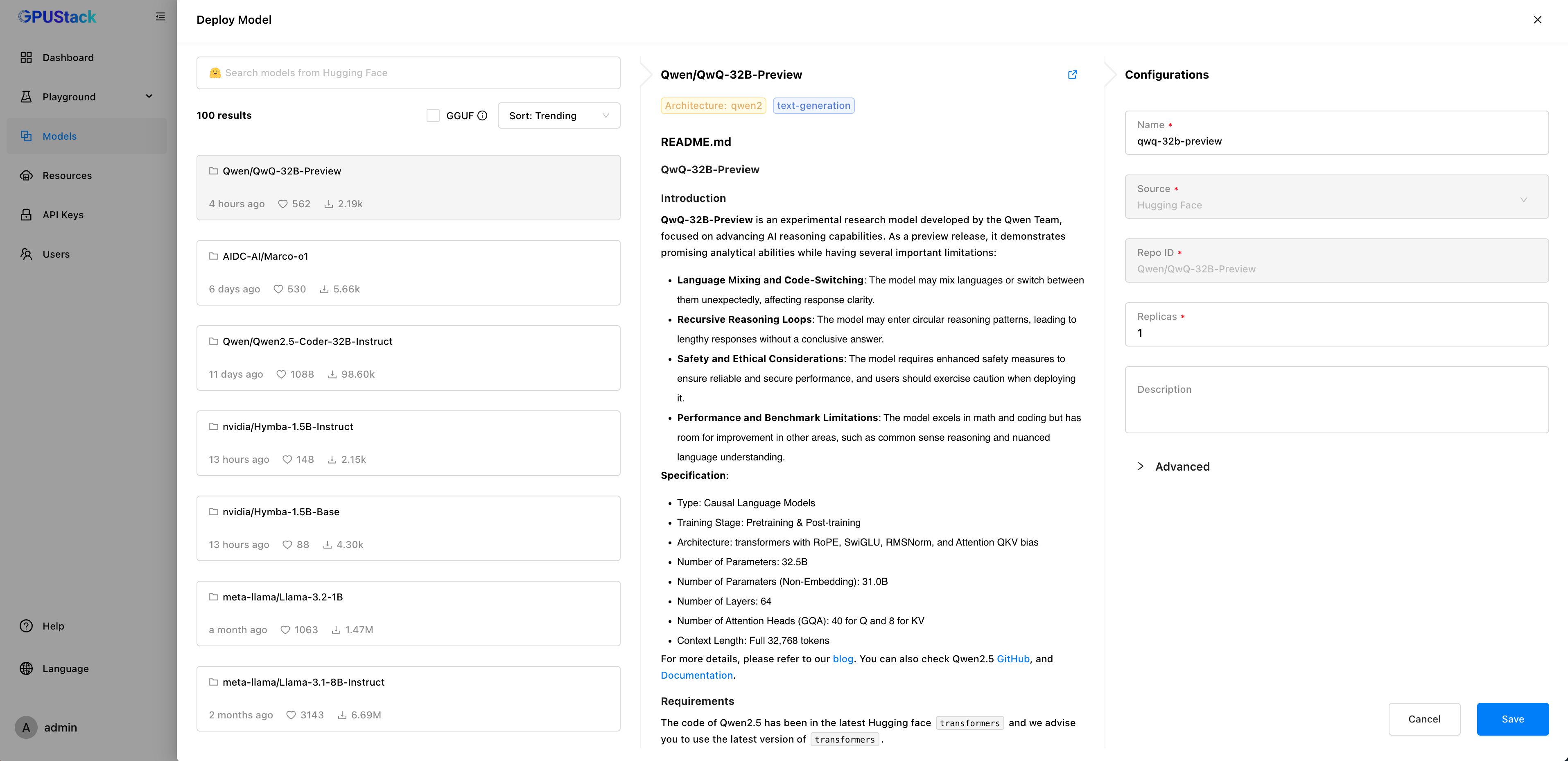
Support for Model Deployment from Hugging Face Mirrors
GPUStack allows you to deploy models from repositories like Hugging Face, ModelScope, and Ollama Registry. However, users in certain regions may face challenges when trying to deploy models from Hugging Face due to network restrictions or latency. While ModelScope and Ollama Registry provide alternatives, their model repositories are more limited compared to Hugging Face.
To address this, GPUStack introduces support for the HF_ENDPOINT environment variable, enabling users to configure a Hugging Face mirror. This allows users to fetch and download models from the mirror during deployment.
When running GPUStack as a systemd or launchd service, the system reads environment variables from the /etc/default/gpustack file. You can configure the mirror by adding the necessary environment variable to this file.
To configure the HF_ENDPOINT on all nodes, follow these steps:
Edit the /etc/default/gpustack file:
xxxxxxxxxxvim /etc/default/gpustackFor example, add the following environment variable to point to your Hugging Face mirror (e.g., https://hf-mirror.com):
xxxxxxxxxxHF_ENDPOINT=https://hf-mirror.comRestart the service to apply the changes:
xxxxxxxxxxsystemctl restart gpustackAfter restarting GPUStack, models deployed from Hugging Face will be retrieved from the configured mirror.
Note: The HF_ENDPOINT must be set on all nodes to ensure consistent model downloads across the cluster.
This also applies to other environment variables.
More Compatible API Integration
In earlier versions, integrating frameworks like OneAPI and RAGFlow with GPUStack required extra steps. These frameworks didn’t support custom OpenAI API paths, so users had to set up a proxy (e.g., Nginx) to map the /v1 endpoint to GPUStack’s /v1-openai endpoint, adding unnecessary complexity to the setup.
To improve the user experience and compatibility, GPUStack v0.4 introduces an alias feature that automatically maps OpenAI API paths from /v1-openai to /v1. This change allows frameworks like OneAPI and RAGFlow, to integrate with GPUStack directly using the /v1 endpoint—without needing a proxy.
Support for PostgreSQL database
Previously, GPUStack used SQLite for data storage, which was perfect for lightweight and edge deployments. However, for production environments, data collection, and integration needs, GPUStack now offers the option to store data in a PostgreSQL database.
During installation, you can specify the PostgreSQL database URL with the --database-url parameter. For example:
xxxxxxxxxxcurl -sfL https://get.gpustack.ai | sh -s - --database-url "postgresql://username:password@host:port/database_name"
By using PostgreSQL, GPUStack provides enhanced data management capabilities and greater scalability.
Expanded support
GPUStack v0.4 provides offline container images, which also resolve glibc dependencies for legacy operating systems such as Ubuntu 18.04 and others running glibc versions earlier than 2.29.
We are actively expanding GPUStack’s compatibility, with ongoing work planned for platforms such as AMD GPU.
GPUStack requires Python >= 3.10. If you’re using a version lower than 3.10, we recommend creating a Python environment using Conda to meet the version requirements.
Other features and fixes
GPUStack v0.4.0 also includes many enhancements and bug fixes based on user feedback, such as:
• Enhanced status messages for model deployment with detailed reasons for issues.
• Resolved timeout errors when loading Hugging Face or ModelScope models in high-latency network environments.
• Improved the display of model logs for large logs.
• Added a command to reset the admin password: gpustack reset-admin-password
These improvements enhance system usability and stability, further improving the user experience.
For other enhancements and bug fixes, see the full changelog:
https://github.com/gpustack/gpustack/releases/tag/v0.4.0
Join Our Community
For more information about GPUStack, please visit: https://gpustack.ai.
If you encounter any issues or have suggestions, feel free to join our Community for support from the GPUStack team and connect with users from around the world.
We are continuously improving the GPUStack project. Before getting started, we encourage you to follow and star our project on GitHub at gpustack/gpustack to receive updates on future releases. Bug report and PRs are welcome and highly appreciated!












{kind=link}