
We’re thrilled to announce the release of our most powerful update yet — GPUStack v0.6 !!!
GPUStack is an open-source MaaS platform designed for enterprise-level deployment. It runs on Linux, Windows, and macOS, and supports heterogeneous GPU clusters built with a wide range of hardware, including NVIDIA, AMD, Apple Silicon, Ascend, Hygon, and Moore Threads.
GPUStack supports a broad range of model types—including LLMs, VLMs, embeddings, rerankers, image generation, speech-to-text, and text-to-speech—and integrates seamlessly with multiple inference engines such as vLLM, MindIE, and llama-box (built on llama.cpp and stable-diffusion.cpp). It also enables coexistence of multiple versions of the same inference engine, providing greater flexibility for deployment and performance tuning.
The platform offers enterprise-grade features such as automatic resource scheduling, fault recovery, distributed inference, heterogeneous inference, request load balancing, resource and model monitoring, user management, and API authentication and authorization.
GPUStack also provides OpenAI-compatible APIs, making it easy to integrate with upper-layer application frameworks like Dify, n8n, LangChain, and LlamaIndex—making it an ideal choice for enterprises building robust AI model serving infrastructure.
At GPUStack, our mission has always been to make it as simple and seamless as possible for users to manage heterogeneous GPU resources and deploy the AI models they need—enabling applications such as RAG, AI agents, and other generative AI use cases.
Delivering an exceptional user experience is at the heart of everything we do. The newly released v0.6 is our most significant update yet, bringing comprehensive improvements to functionality, performance, stability, and overall usability across the platform.
What’s New in GPUStack v0.6
GPUStack v0.6 introduces a wide range of major updates, with key highlights including:
Multi-node distributed inference with vLLM
Production-ready support for multi-node inference using vLLM, enabling the deployment of large models like DeepSeek R1 / V3 that exceed the capacity of a single GPU machine.
MindIE support for Ascend chips
Native support for the MindIE inference engine on Ascend 910B and 310P devices, delivering optimized performance for model inference on Ascend’s AI hardware.
Model compatibility checks
Built-in compatibility eualuation to ensure models can be deployed smoothly. Current checks include model architecture support, OS compatibility, resource availability, and local path accessibility—with more checks being added to continuously improve the deployment experience.
Model download management
Centralized management of downloaded models, with support for initiating single-node or multi-node download tasks without consuming GPU resources, and the ability to register locally stored models in the UI for unified management.
Automatic recovery
Models can now automatically recover from runtime failures, improving system robustness and reliability.
Port exposure optimization
Streamlined port exposure: all inference requests are now routed through the worker proxy, eliminating the need to expose model instance ports to server directly. This reduces open ports by over 96%, with full support for custom port configurations.
Enhanced internationalization
With users across more than 100 countries and regions, GPUStack now includes Russian and Japanese language support, further accelerating global adoption and improving accessibility for non-English users.
Comprehensive UI/UX improvements
Every detail of the interface has been polished to deliver the best-in-class user experience for model deployment and inference.
This release includes over 100 enhancements, bug fixes, performance improvements, and usability refinements, making GPUStack more powerful, stable, and user-friendly than ever before—ready to support your AI deployments at scale.
For more information about GPUStack, visit:
GitHub repo: https://github.com/gpustack/gpustack
User guide: https://docs.gpustack.ai
Key Features
Multi-Node Distributed Inference with vLLM
As LLMs continue to scale in size, traditional single-node GPU setups are increasingly unable to meet the demands of real-world inference workloads. To address this challenge, the latest version of GPUStack introduces production-ready support for vLLM multi-node distributed inference. By partitioning models by tensor or layer and distributing them across multiple nodes, GPUStack enables inference for ultra-large models such as DeepSeek R1 and DeepSeek V3.
GPUStack currently supports two types of distributed inference engines:
llama-box: Heterogeneous Distributed Inference (for development and testing)
- Compatible with Linux, Windows, and macOS.
- Supports mixed hardware environments, allowing different GPU brands, and OSs to participate in the same cluster.
- Enables quick setup of lightweight, heterogeneous inference clusters on desktops or small servers.
- Ideal for R&D, model validation, and compatibility testing.
vLLM: Homogeneous Distributed Inference (for production environments)
- Designed for multi-node deployments on Linux servers.
- Assumes a consistent hardware setup across nodes (e.g., identical GPU models, counts, and memory).
- Supports both tensor parallelism and pipeline parallelism for high throughput inference.
- Best suited for production workloads requiring low latency and high concurrency.
With distributed inference powered by both vLLM and llama-box, GPUStack covers the entire model deployment lifecycle—from flexible experimentation during development to robust, scalable serving in production. Developers can prototype and validate models using llama-box, then seamlessly transition to vLLM for stable, high-performance inference at scale.
Support for Ascend MindIE
In earlier versions, GPUStack offered initial support for Ascend 910B and 310P NPUs through the llama-box inference engine. However, due to limited operator coverage and an immature ecosystem, practical use cases were constrained—only partial quantization formats were supported, and performance and stability lagged behind Ascend’s official inference framework.
To significantly improve model inference on Ascend NPUs, GPUStack now integrates the MindIE inference engine, delivering a more stable and higher-performance solution for both 910B and 310P hardware.
MindIE is Ascend’s official high-performance deep learning inference framework, designed for accelerated execution, easy debugging and tuning, and rapid deployment. It offers industry-leading performance on Ascend hardware, backed by a mature software-hardware co-optimization ecosystem. As a result, MindIE has become the go-to solution for deploying inference workloads on NPUs.
GPUStack has completed its initial integration with MindIE, and in certain scenarios, this brings multi-fold speedups compared to the previous llama-box backend. Looking ahead, GPUStack will continue optimizing MindIE support while also exploring additional inference engines on the Ascend platform—such as vLLM-Ascend—to better serve diverse inference needs across different scenarios.
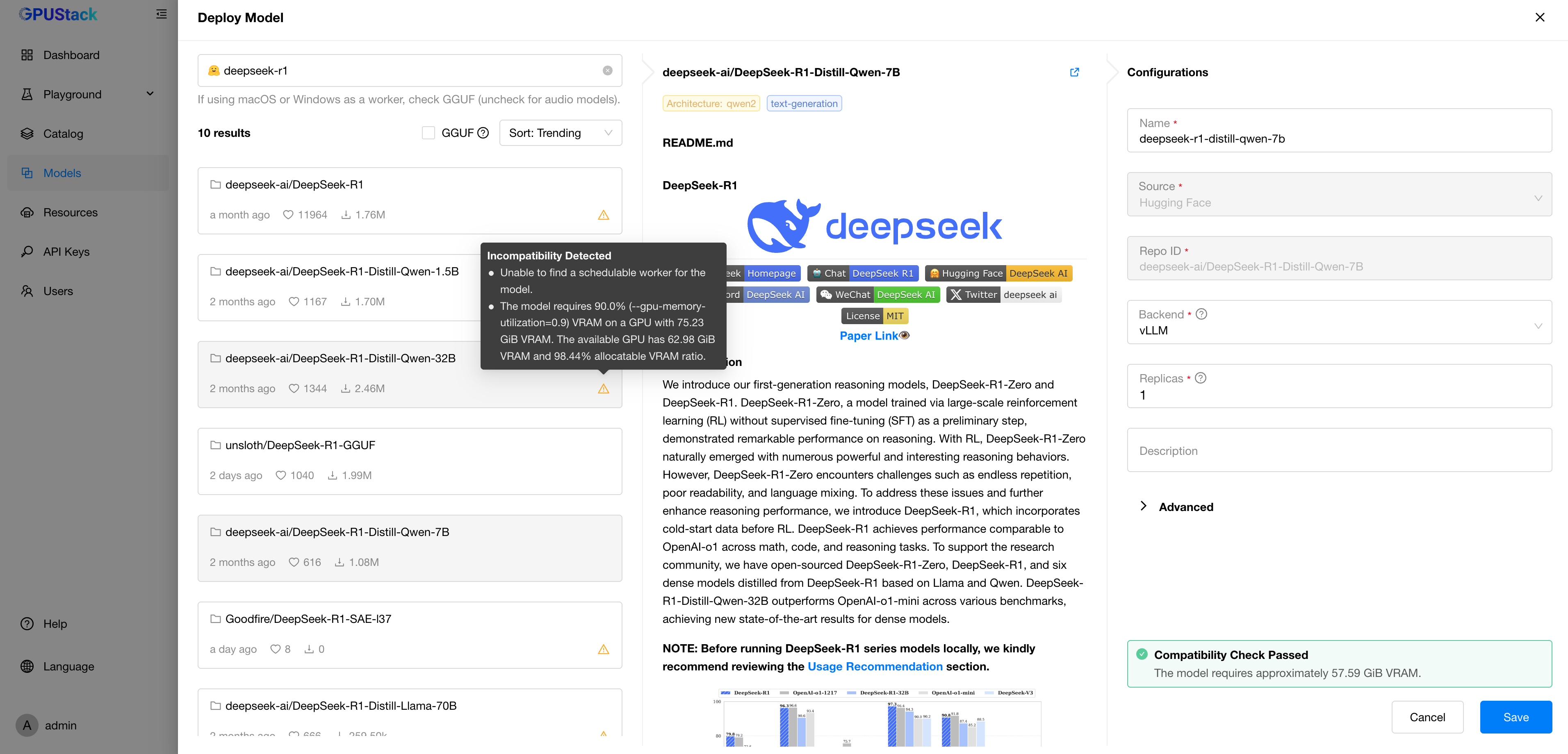
Model Compatibility Check
In previous versions, deploying models directly from Hugging Face or ModelScope occasionally led to failures. Common causes included insufficient GPU memory, OS incompatibility with the inference engine, unsupported model architectures, or misconfigured local paths. These issues not only wasted time but also disrupted the user experience.
To address this, GPUStack now introduces a Model Compatibility Check mechanism. Before deployment, the platform automatically evaluates the compatibility between the selected model and the runtime environment—covering key aspects such as engine support for the model architecture, OS compatibility, GPU resource availability, and local path validity. This preemptive check helps surface potential issues early, providing clear and actionable feedback to avoid unnecessary deployment failures.
This feature will continue to evolve with expanded checks and broader platform support, ensuring that users can achieve stable and efficient model deployment across diverse environments.
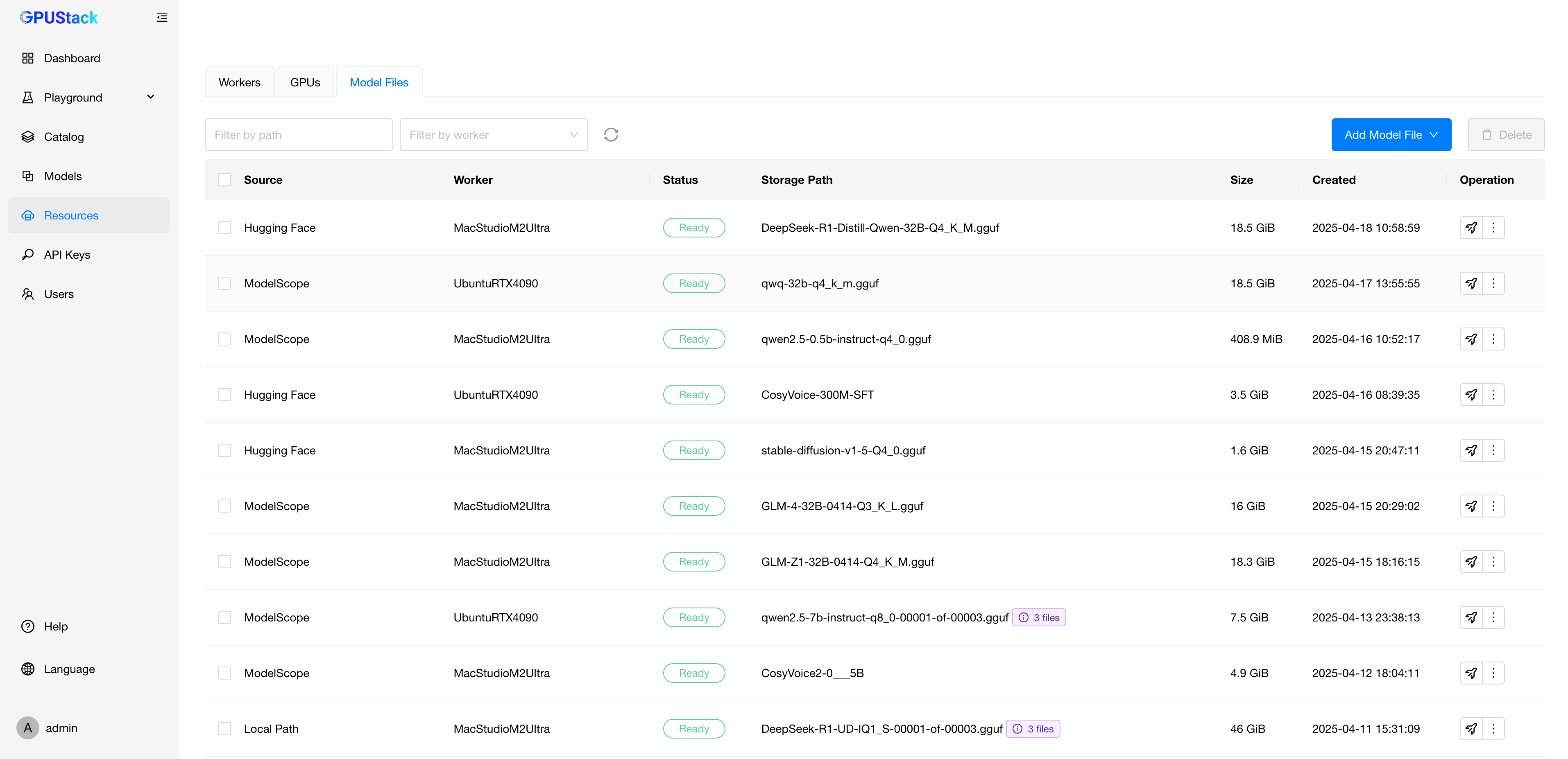
Model Download Management
Efficient distribution and centralized management of model files have long been critical challenges in the deployment process. Traditionally, model downloads are automatically triggered during instance startup—this not only consumes valuable GPU resources but also often requires additional manual intervention. Moreover, GPUStack previously lacked the capability to manage model files that users had manually downloaded to local directories, leading to inefficient deployments and a fragmented management experience.
To address these limitations, GPUStack introduces a new Model Download Management feature. Users can now manually initiate model download tasks for multiple target hosts directly from the UI—without using any GPU resources. Once downloaded, model files across nodes are centrally tracked and visualized in the UI, significantly enhancing deployment flexibility and operational efficiency.
Additionally, GPUStack supports registering existing local model paths for unified management. This makes the system well-suited for a variety of deployment scenarios, including private or offline environments. With this feature, GPUStack not only supports custom model download workflows but also improves its ability to handle multi-node distributed deployments—streamlining the process and enabling better coordination at scale.
Automatic Model Failure Recovery
In production environments where high availability and stability are critical, the reliability of model inference services plays a vital role. To enhance this further, GPUStack introduces an automatic model failure recovery mechanism. When a model encounters a failure, GPUStack automatically triggers a recovery process, promptly attempting to restart the model and ensuring uninterrupted service.
To prevent excessive and ineffective restarts, GPUStack implements an exponential backoff strategy with a maximum delay of 5 minutes. This approach gradually increases the restart delay if the failure persists, helping to avoid unnecessary resource consumption. Overall, the model failure recovery mechanism introduced in v0.6 significantly improves fault tolerance, making model inference in production environments more resilient.
Port Exposure Optimization
In previous releases, each worker node needed to expose a dedicated port to the server node for every model instance, enabling the server to route inference requests accordingly. However, at scale, this design introduced several issues: port mapping became excessive, container startup and shutdown slowed down, and port conflicts occurred frequently. Misconfigured firewalls also led to occasional inference failures. Additionally, users couldn’t customize the range of exposed ports.
With v0.6, we’ve completely rearchitected the port exposure mechanism. Inference requests are now routed through a unified proxy on each worker, eliminating the need to expose individual ports for every model instance.
This new design reduces the exposed port range by over 96%, dramatically simplifying deployment and minimizing operational risk. It also introduces user-configurable port ranges, making GPUStack more adaptable to different network environments and security policies—delivering a more streamlined, stable deployment experience.
Enhanced Internationalization Support
GPUStack is now used in over 100 countries and regions around the world. As our global user base continues to expand, we’re committed to delivering a consistent, accessible experience for developers of all language backgrounds.
With this release, we’ve added support for Russian and Japanese—marking an important milestone in GPUStack’s journey toward full internationalization.
By expanding our multilingual capabilities, GPUStack is creating a more inclusive and efficient experience for the global community. Looking ahead, we’ll continue investing in localization to provide comprehensive, high-quality support for users worldwide.
Comprehensive UI/UX Enhancements
Your feedback continues to drive our progress. If you have any ideas, questions, or suggestions, we’d love to hear from you. We’re committed to listening, improving, and making GPUStack even better with every release.
In this release, we’ve introduced wide-ranging improvements to the UI and UX—from how information is presented to the finer points of user interaction. Nearly every detail has been thoughtfully refined to deliver a smoother, more intuitive experience.
Many of these enhancements were inspired by feedback from our users over the past few months. Every suggestion mattered, and your input played a crucial role in shaping this update.
From day one, our goal has been simple: to build the most user-friendly MaaS platform in the industry. With every release, GPUStack moves one step closer to that vision.
Your feedback continues to drive our progress. If you have any ideas, questions, or suggestions, we’d love to hear from you. We’re committed to listening, improving, and making GPUStack even better with every release.
Join Our Community
For more information about GPUStack, please visit our GitHub repository: https://github.com/gpustack/gpustack.
If you have any suggestions or feedback about GPUStack, feel free to open an issue on GitHub.
Before trying out GPUStack or submitting an issue, we kindly ask you to give us a Star ⭐️ on GitHub to show your support.
We also warmly welcome contributions from the community — let’s build this open-source project together!











{kind=link}