
llama.cpp is the underlying implementation for Ollama, LMStudio, and many other popular projects, and is one of the inference backends in GPUStack. It offers the GGUF model format - a file format designed for optimized inference, allowing models to load and run quickly.
llama.cpp also supports quantized models, which reduces storage and computational demands while preserving high model accuracy. This makes it possible to deploy LLMs efficiently on desktops, embedded devices, and resource-limited environments, enhancing inference speed.
Today, we bring a tutorial on how to convert and quantize GGUF models and upload them to HuggingFace.
Signing up and configuring your Hugging Face Account
- Signing up Hugging Face
First, go to https://huggingface.co/join and sign up for a Hugging Face account.
- Configuring SSH Key
Add your SSH public key to Hugging Face, to get your SSH key, run the command below. (If it doesn't exist, generate SSH key with ssh-keygen -t rsa -b 4096)
xxxxxxxxxxcat ~/.ssh/id_rsa.pubOn Hugging Face, go to "Account > Settings > SSH and GPG Keys" to add your SSH key. This provides authentication for uploading model later.
Preparing llama.cpp
Create and activate a Conda environment (If Conda is not installed, refer to the installation guide:https://docs.anaconda.com/miniconda/):
xxxxxxxxxxconda create -n llama-cpp python=3.12 -yconda activate llama-cppwhich pythonpip -VClone the latest llama.cpp release and build it as follows:
xxxxxxxxxxcd ~git clone -b b4034 https://github.com/ggerganov/llama.cpp.gitcd llama.cpp/pip install -r requirements.txtbrew install cmakemake
After building, run the following command to confirm:
xxxxxxxxxx./llama-quantize --help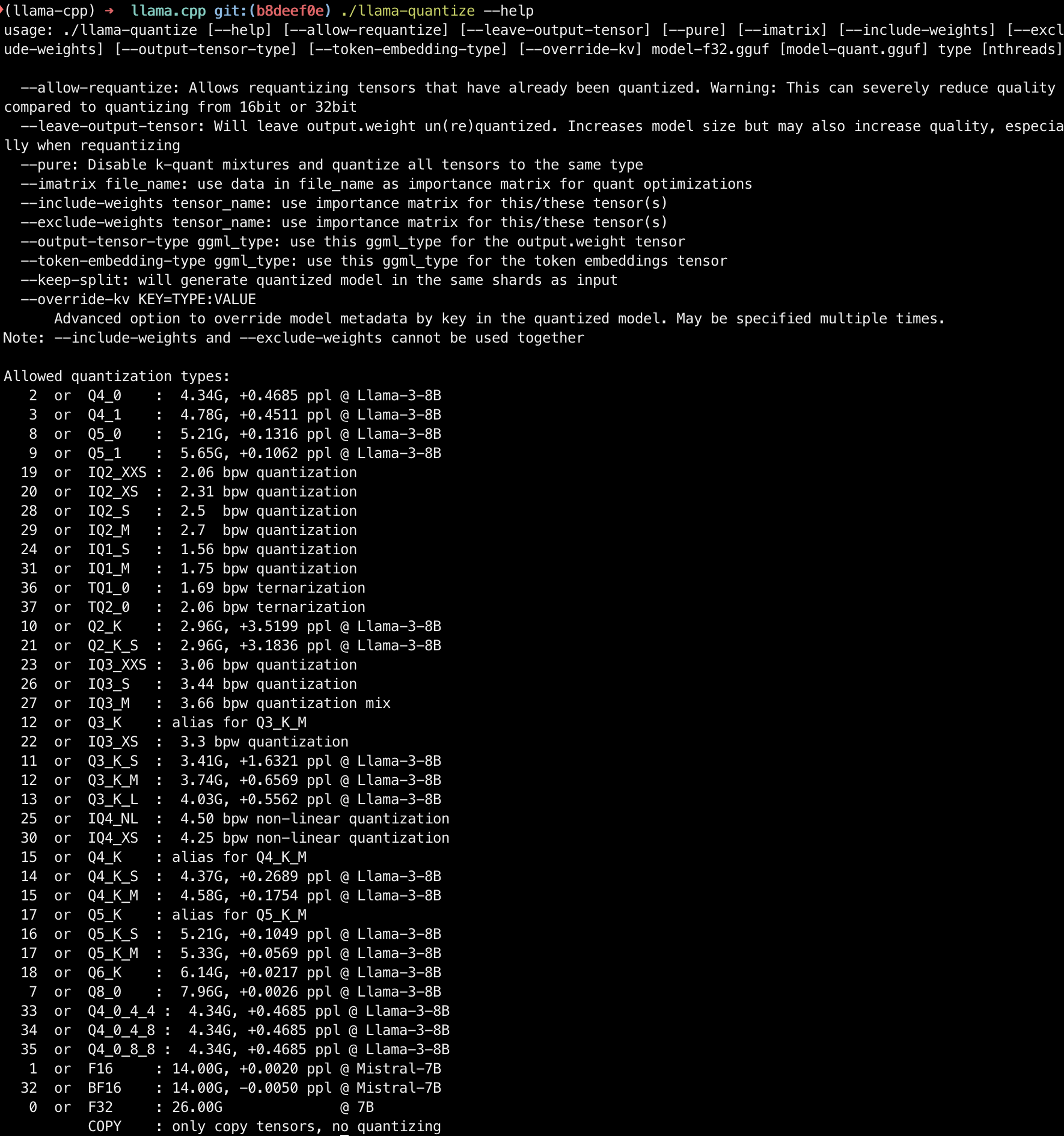
Downloading original model
Download the original model you want to convert to GGUF model and quantize.
Download model from Hugging Face using huggingface-cli. First, ensure it is installed:
xxxxxxxxxxpip install -U huggingface_hubHere we download meta-llama/Llama-3.2-3B-Instruct . This is a Gated model, so we need to request access on Hugging Face before downloading:
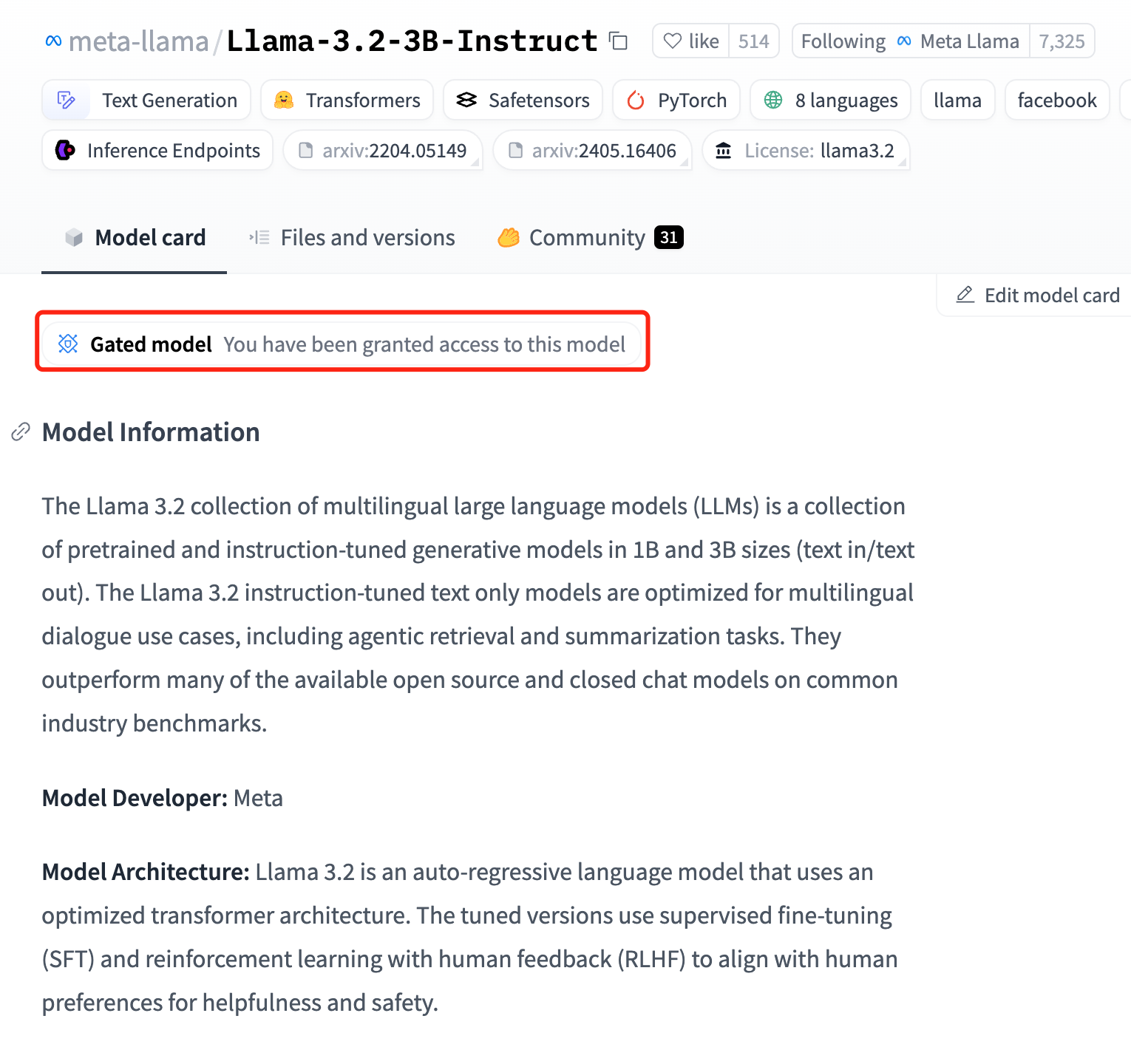
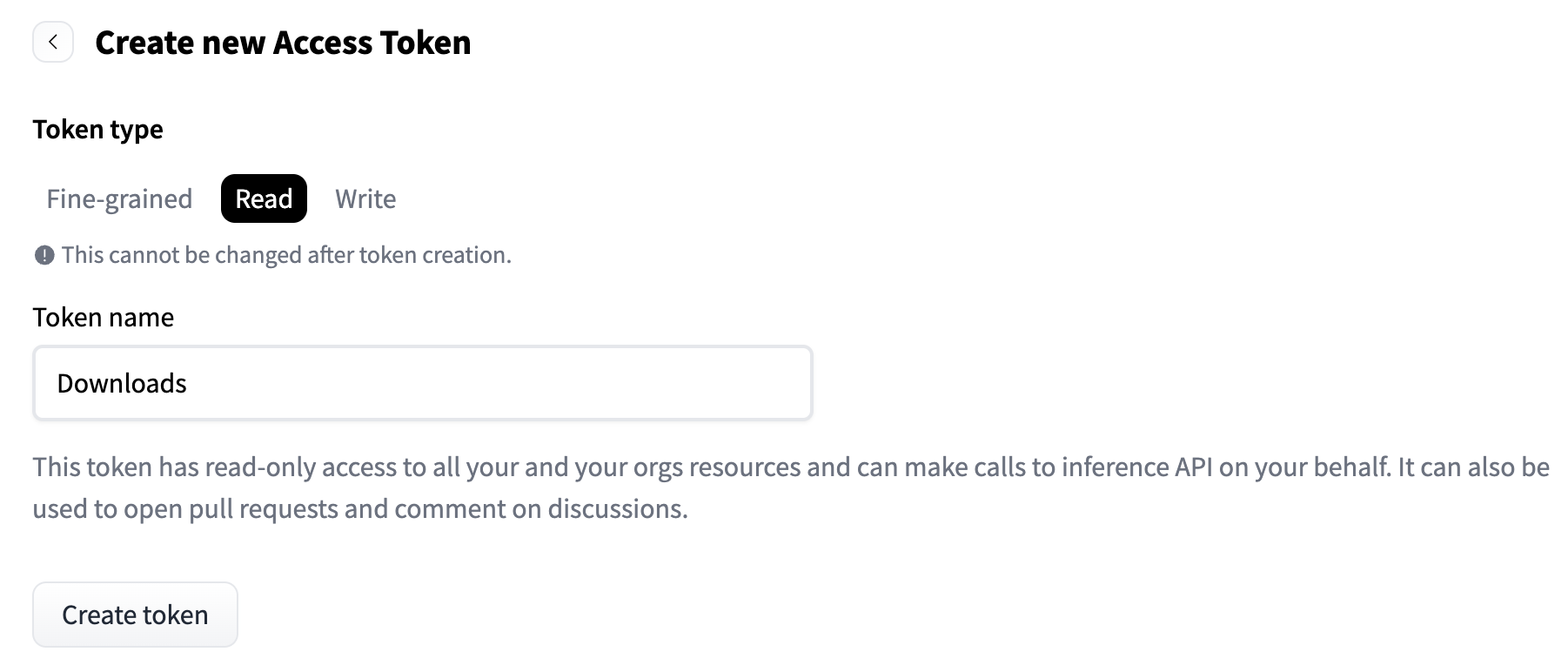
On Hugging Face, go to "Account > Access Tokens" to generate an access token with Read permissions:
Downloading meta-llama/Llama-3.2-3B-Instruct and using --local-dir parameter to specify the placed directory, and --token to specify the access token created previously.
xxxxxxxxxxmkdir ~/huggingface.cocd ~/huggingface.co/huggingface-cli download meta-llama/Llama-3.2-3B-Instruct --local-dir Llama-3.2-3B-Instruct --token hf_abcdefghijklmnopqrstuvwxyzConvert to GGUF and quantize
Create a script to convert model to GGUF format and quantize the model:
xxxxxxxxxxcd ~/huggingface.co/vim quantize.shFill in the following content and modify the directory paths for llama.cpp and huggingface.co to the actual paths in your current environment, ensuring they are absolute paths. Change the gpustack in the d variable to your HuggingFace username:
xxxxxxxxxx
llama_cpp="/Users/gpustack/llama.cpp"b="/Users/gpustack/huggingface.co"
export PATH="$PATH:${llama_cpp}"
s="$1"n="$(echo "${s}" | cut -d'/' -f2)"d="gpustack/${n}-GGUF"
# prepare
mkdir -p ${b}/${d} 1>/dev/null 2>&1pushd ${b}/${d} 1>/dev/null 2>&1git init . 1>/dev/null 2>&1
if [[ ! -f .gitattributes ]]; then cp -f ${b}/${s}/.gitattributes . 1>/dev/null 2>&1 || true echo "*.gguf filter=lfs diff=lfs merge=lfs -text" >> .gitattributesfiif [[ ! -d assets ]]; then cp -rf ${b}/${s}/assets . 1>/dev/null 2>&1 || truefiif [[ ! -d images ]]; then cp -rf ${b}/${s}/images . 1>/dev/null 2>&1 || truefiif [[ ! -d imgs ]]; then cp -rf ${b}/${s}/imgs . 1>/dev/null 2>&1 || truefiif [[ ! -f README.md ]]; then cp -f ${b}/${s}/README.md . 1>/dev/null 2>&1 || truefi
set -e
pushd ${llama_cpp} 1>/dev/null 2>&1
# convert
[[ -f venv/bin/activate ]] && source venv/bin/activateecho "#### convert_hf_to_gguf.py ${b}/${s} --outfile ${b}/${d}/${n}-FP16.gguf"python3 convert_hf_to_gguf.py ${b}/${s} --outfile ${b}/${d}/${n}-FP16.gguf
# quantize
qs=( "Q8_0" "Q6_K" "Q5_K_M" "Q5_0" "Q4_K_M" "Q4_0" "Q3_K" "Q2_K")for q in "${qs[@]}"; do echo "#### llama-quantize ${b}/${d}/${n}-FP16.gguf ${b}/${d}/${n}-${q}.gguf ${q}" llama-quantize ${b}/${d}/${n}-FP16.gguf ${b}/${d}/${n}-${q}.gguf ${q} ls -lth ${b}/${d} sleep 3done
popd 1>/dev/null 2>&1
set +eStart converting the model to a FP16 GGUF model, and quantize the model using the following methods: Q8_0, Q6_K, Q5_K_M, Q5_0, Q4_K_M, Q4_0, Q3_K, and Q2_K.
xxxxxxxxxxbash quantize.sh Llama-3.2-3B-InstructAfter the script is executed, confirm the successful conversion to the FP16 GGUF model and the quantized GGUF model:
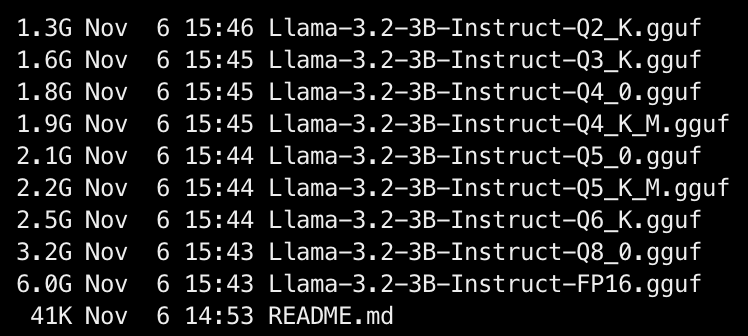
The model is stored in the directory under the corresponding username:
xxxxxxxxxxll gpustack/Llama-3.2-3B-Instruct-GGUF/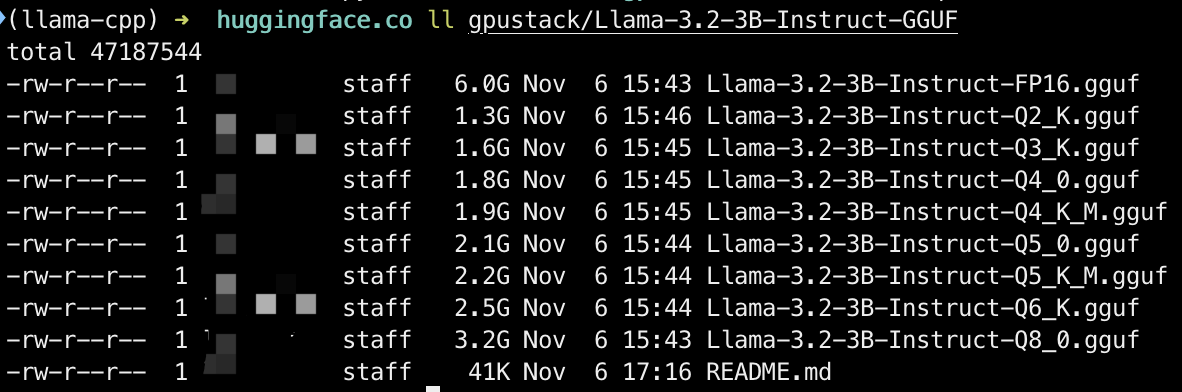
Uploading the Model to HuggingFace
Go to HuggingFace, click on your profile and select New Model to create a model repository with the same name, formatted as original-model-name-GGUF.
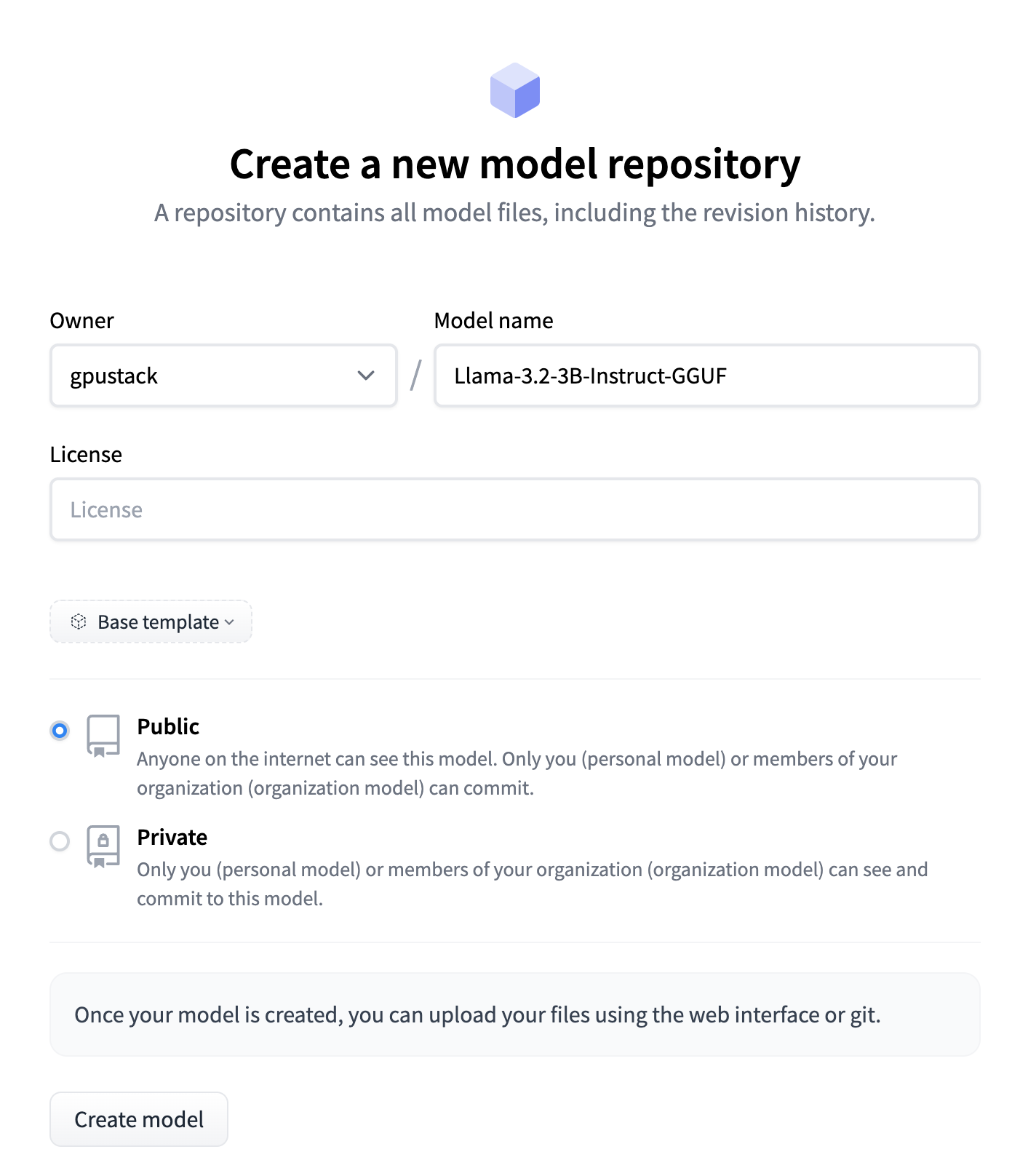
Update the README for model:
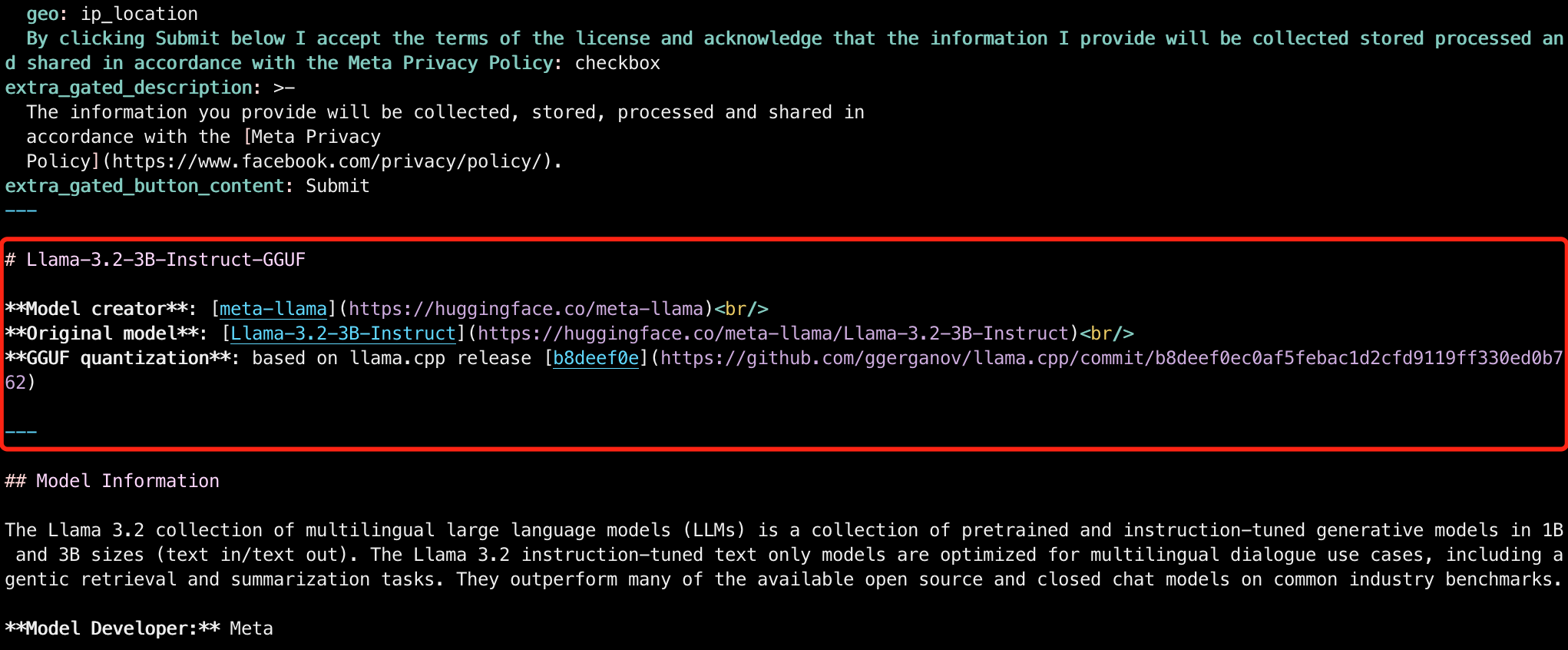
xxxxxxxxxxcd ~/huggingface.co/gpustack/Llama-3.2-3B-Instruct-GGUFvim README.mdFor maintainability, after the metadata, record the original model and the commit information for the llama.cpp. Ensure to modify according to the actual information:
xxxxxxxxxx# Llama-3.2-3B-Instruct-GGUF
**Model creator**: [meta-llama](https://huggingface.co/meta-llama)<br/>**Original model**: [Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct)<br/>**GGUF quantization**: based on llama.cpp release [b8deef0e](https://github.com/ggerganov/llama.cpp/commit/b8deef0ec0af5febac1d2cfd9119ff330ed0b762)
---
Installing Git LFS for managing large files:
xxxxxxxxxxbrew install git-lfsAdd the remote repository:
xxxxxxxxxxgit remote add origin git@hf.co:gpustack/Llama-3.2-3B-Instruct-GGUFAdd files, confirm files to be committed with git ls-files, and use git lfs ls-files to verify all .gguf files are managed by Git LFS:
xxxxxxxxxxgit add .git ls-filesgit lfs ls-files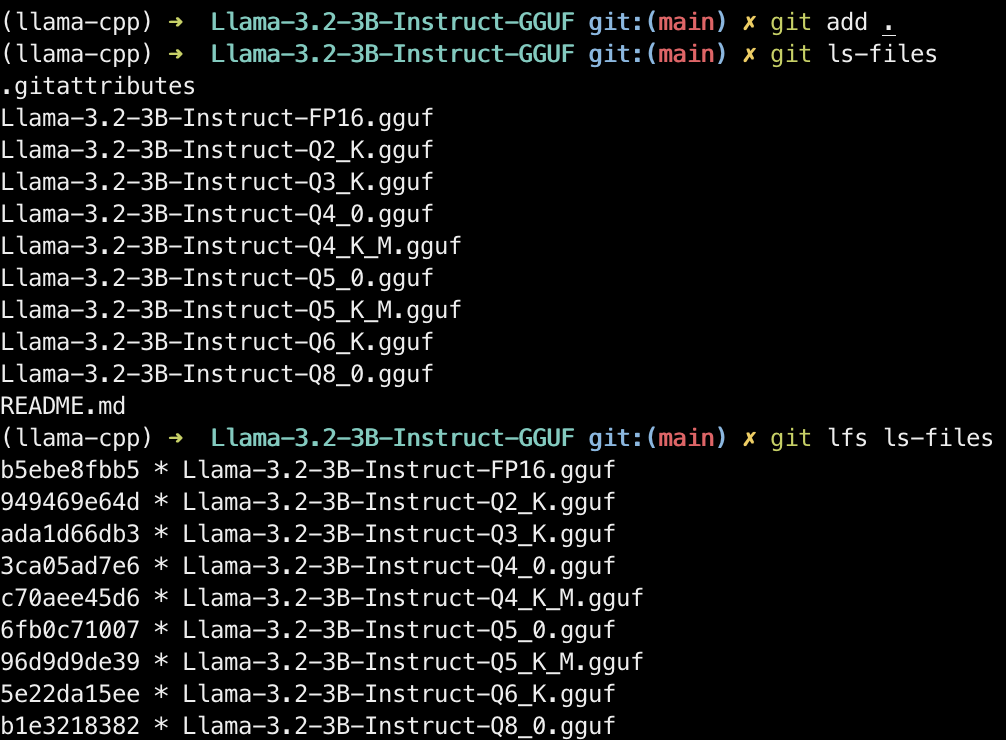
Enable large file (larger than 5GB) uploads on HuggingFace. Log into Hugging Face via CLI, entering the token created in the Downloading original model section above:
xxxxxxxxxxhuggingface-cli loginEnable large file uploads for the current directory:
xxxxxxxxxxhuggingface-cli lfs-enable-largefiles .
Upload the model to Hugging Face:
xxxxxxxxxxgit commit -m "feat: first commit" --signoffgit push origin main -fAfter uploading, verify the uploaded model files on Hugging Face.
If the upload is unsuccessful, try using
huggingface-clito upload. Make sure to use an access token with Write permissions.
Conclusion
In this tutorial, we introduced how to use llama.cpp to convert and quantize GGUF models and upload them to HuggingFace.
The flexibility and efficiency of llama.cpp make it an ideal choice for model inference in resource-limited scenarios, with widespread applications. GGUF is the required model format for running models in llama.cpp, and we hope this tutorial is helpful for you to manage GGUF models.












{kind=link}